Engineering LLM Loadtester — 비개발직군용 LLM 서빙 벤치마킹 도구
Overview
비개발직군도 브라우저에서 바로 LLM 서빙 성능을 테스트할 수 있는 Web 기반 벤치마킹 도구
상사로부터 "LLM 서버의 동시 접속 가능 인원은 몇 명인가?"라는 질문을 받았습니다. 인프라 평가와 성능 테스트가 담당자에게 축적되지 않고, 필요할 때마다 임시로 담당자를 정해 처리하는 구조가 문제였습니다. "비개발자도 누구나 사용 가능한 사내 공용 LLM LoadTester"를 제안하고 직접 만들었습니다.
GitHub Stars 2 · WIGTN-Coding 플러그인으로 주말에 MVP를 완성한 후 고도화했습니다.
주요 성과
- Ex-Google ML/AI 엔지니어(NextToken 빌더)로부터 — 콜드 아웃리치 수신
- 이중 교차 검증 시스템 — Prometheus ±5% + Docker ±10%
- Adapter Pattern으로 단일 인터페이스 대응 — vLLM · SGLang · Ollama · Triton
- GitHub Actions CI — 118 테스트
- WIGTN-Coding 플러그인으로 — 주말에 MVP 완성
링크
외부 반응
Ex-Google ML/AI 엔지니어(NextToken 빌더)로부터 콜드 아웃리치 메일을 수신했습니다. GitHub 프로필에서 engineering-llm-loadtester 레포를 발견하고 "quite relevant"하다며 연락해 주셨습니다. 실제로 프로젝트 위에 interactive app을 만들어 피드백을 주고받는 경험을 했습니다.
왜 만들었나
실무 배경
인프라 성능 테스트가 특정 담당자에게만 가능한 구조였습니다. LLM 서빙 성능을 평가하려면 CLI 도구(llmperf, vllm benchmark 등)를 직접 다뤄야 했고, 영업팀·MLOps·PM은 접근 자체가 어려웠습니다.
해결 방향
UI에서 직접 조정 가능한 반복 테스트 환경을 구축했습니다. 입력(타겟 서버, 트래픽 규모, 프롬프트, SLO 기준값)은 유연하게, 출력(TTFT, TPOT, p99, Goodput)은 데이터 기반으로 명확하게 제공합니다. "누군가를 거치지 않고 직접 도전할 수 있는 Fast Build의 매력"입니다.
핵심 기능
LLM 특화 메트릭
- TTFT (Time To First Token) — 첫 토큰까지의 응답 시간
- TPOT (Time Per Output Token) — 토큰당 생성 시간
- Goodput — SLO 임계값 기반 유효 처리량: "TTFT 500ms 이내 + TPOT 50ms 이내 요청 비율"
- E2E Latency / ITL / Throughput — tiktoken 기반 정확한 토큰 카운팅
실시간 모니터링
WebSocket 기반 진행 상황 + pynvml GPU 메트릭(VRAM, 온도, 사용률)을 실시간으로 수집합니다.
AI 분석 리포트
Claude API 기반으로 벤치마크 결과를 자동 분석합니다. 병목 구간 식별 + 최적 GPU 인프라 자동 추천(필요 GPU = ceil(목표 동시성 / 현재 최대 동시성) × (1 + headroom)) 기능을 제공합니다.
검증 시스템 (Validation Loop)
- Prometheus 메트릭 검증 — 측정값 ±5% 허용 범위 내 교차 확인
- Docker 로그 검증 — 컨테이너 레벨 ±10% 허용 범위 내 재검증
- Adapter Pattern: vLLM · SGLang · Ollama · Triton 등 OpenAI 호환 서버 단일 인터페이스 대응
Service Flow
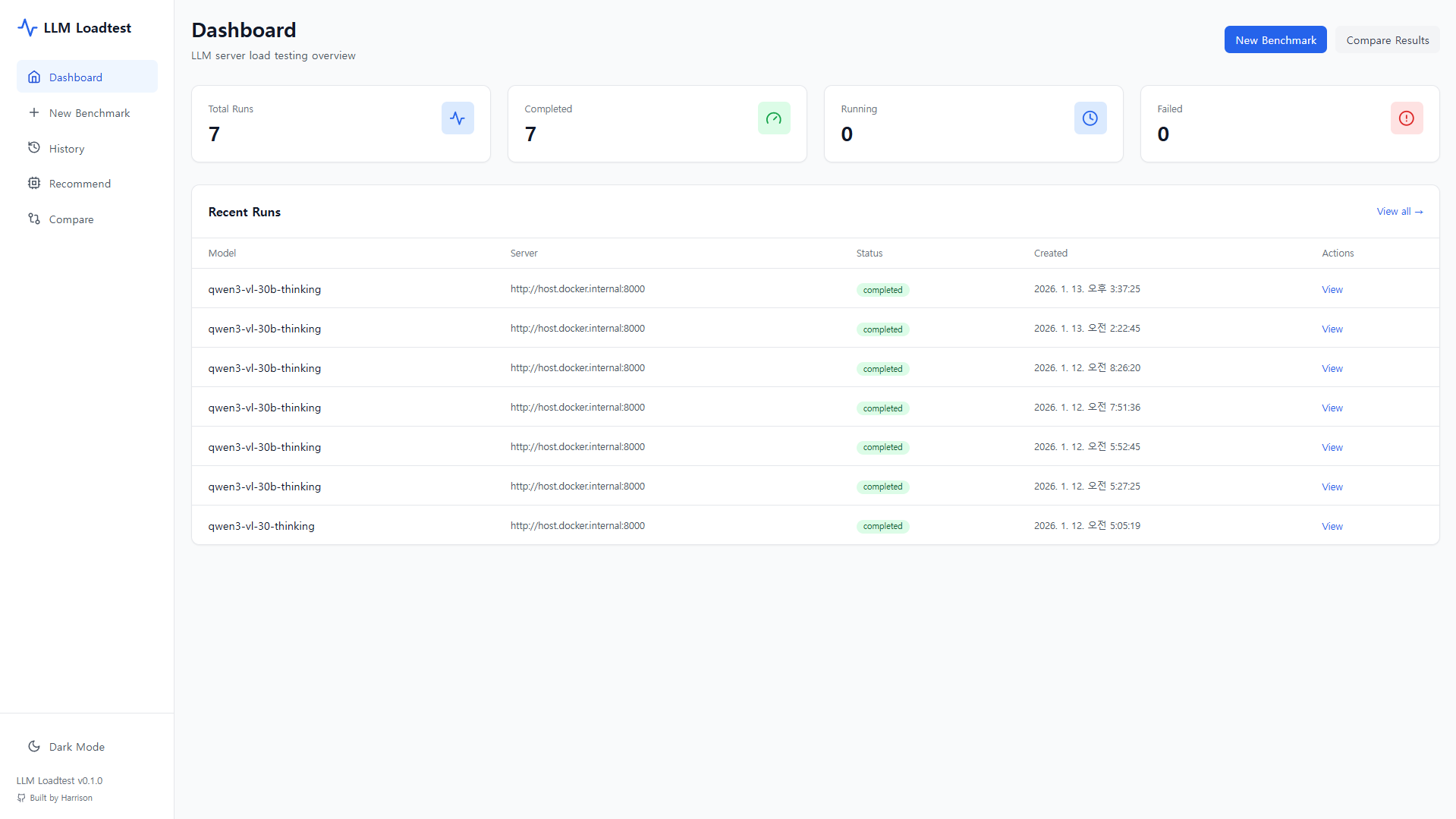
1. 대시보드 — 벤치마크 현황 및 히스토리
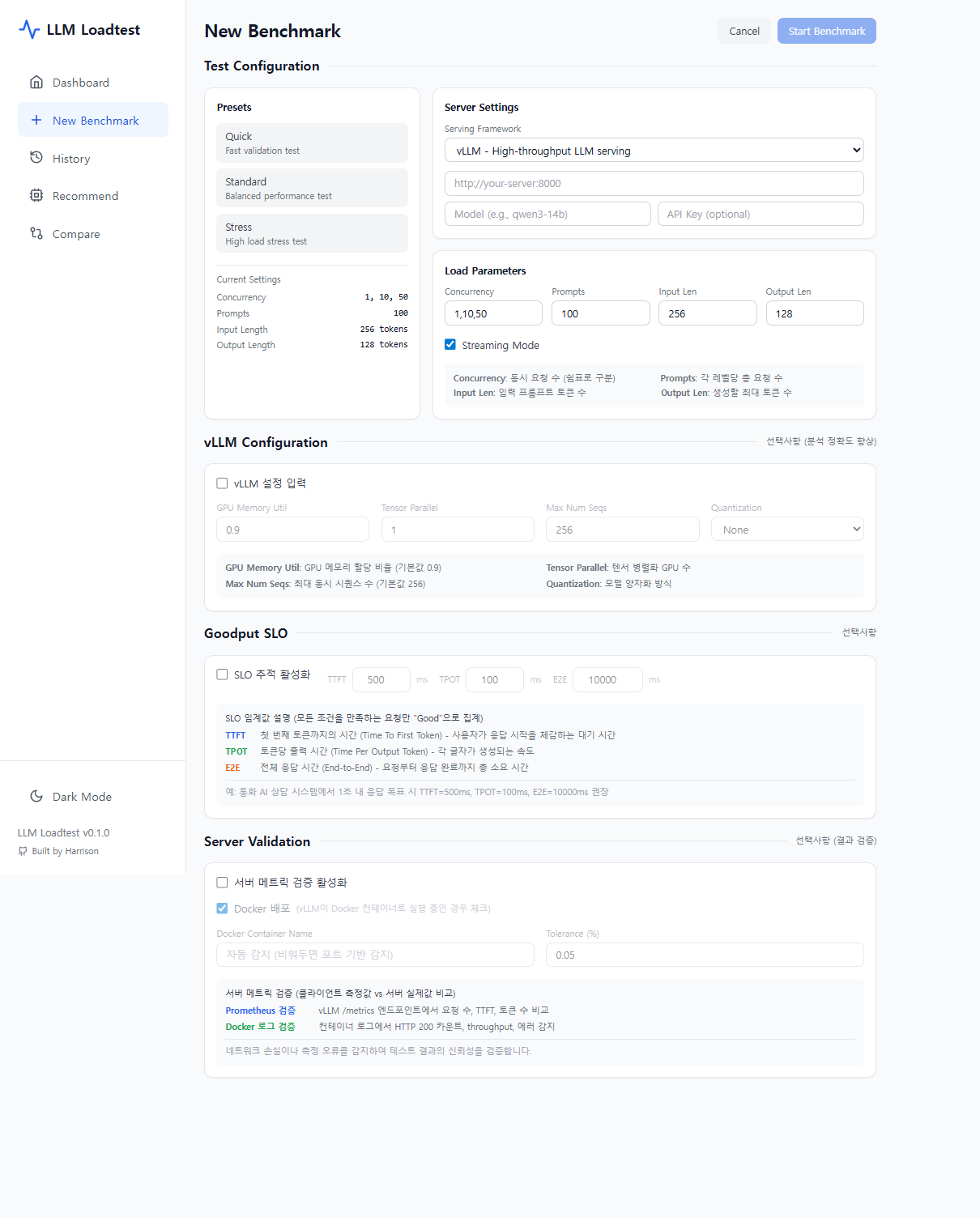 2. 새 벤치마크 — 설정 및 실행
2. 새 벤치마크 — 설정 및 실행
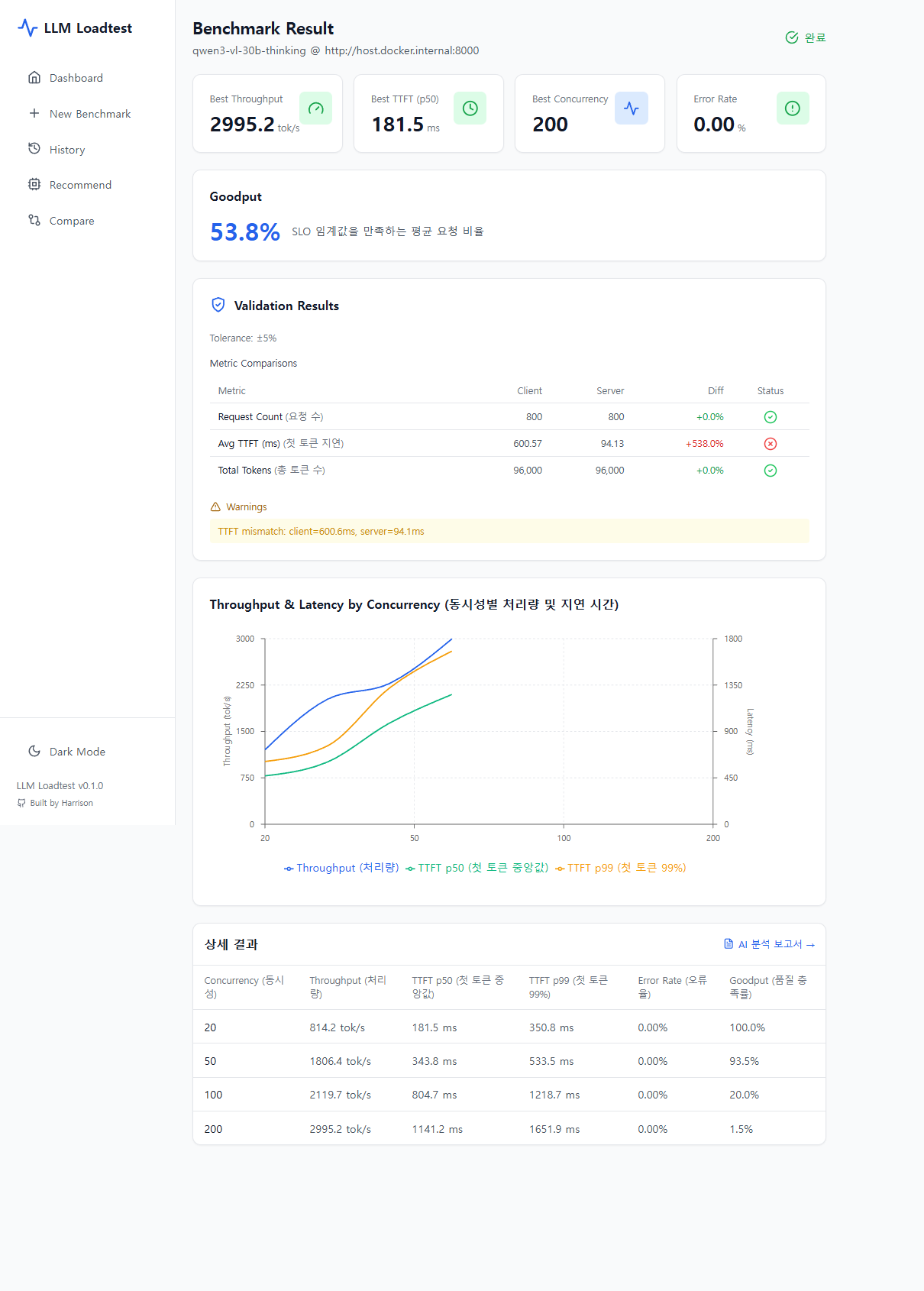 3. 결과 — 메트릭 차트 및 Goodput 분석
3. 결과 — 메트릭 차트 및 Goodput 분석
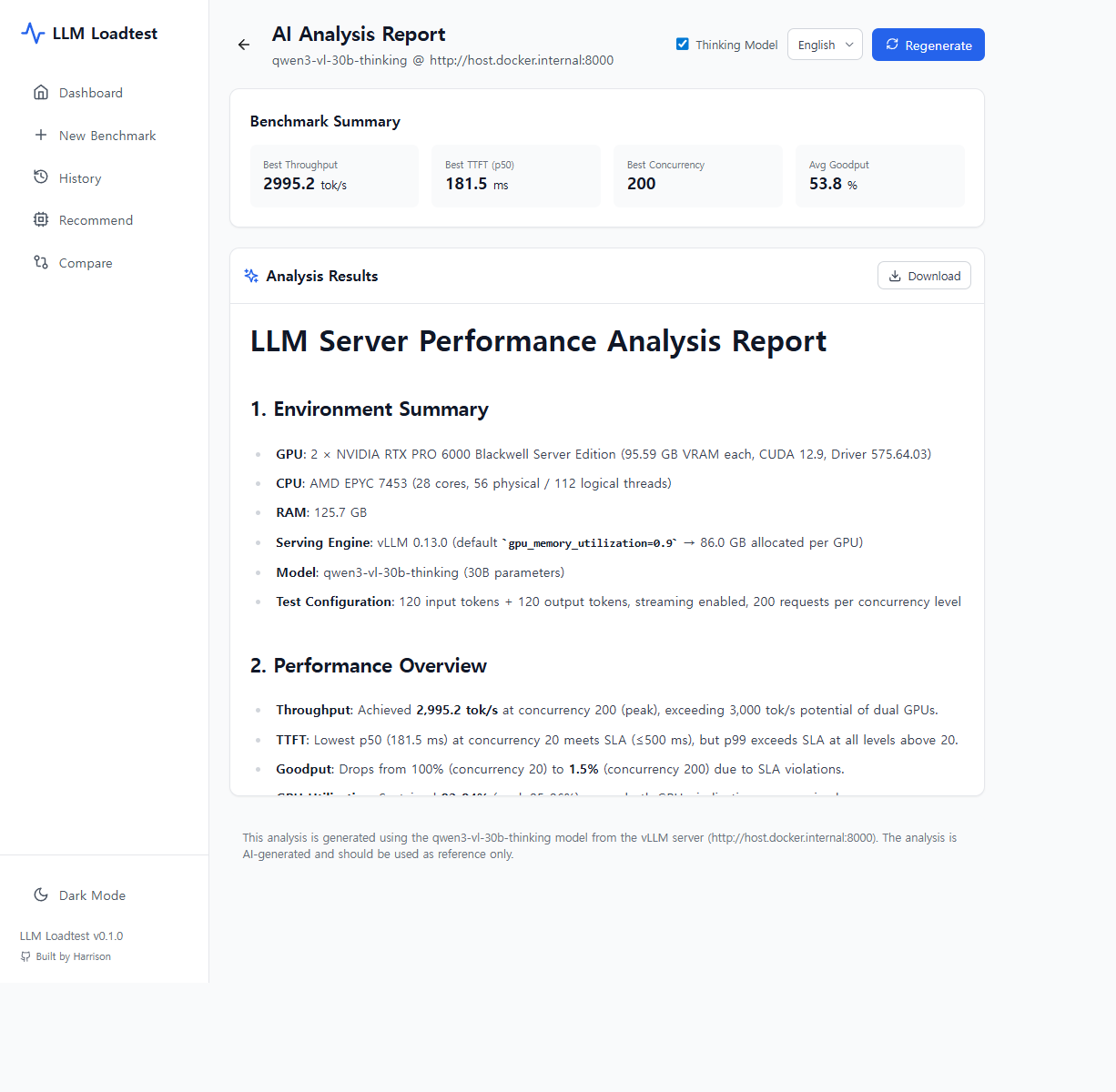 4. AI 분석 리포트 자동 생성
4. AI 분석 리포트 자동 생성
Tech Stack
Backend
- API: Python 3.12, FastAPI, asyncio
- CLI: Typer (터미널 직접 사용 가능)
- GPU 모니터링: pynvml
- 검증: Prometheus + Docker 이중 교차 검증
Frontend
- Web: Next.js, React, Recharts (메트릭 시각화)
- 실시간: WebSocket 기반 진행 상황 스트리밍
Infrastructure
- Docker: docker-compose 원클릭 배포
- CI: GitHub Actions (118 테스트)
- AI: Claude API (분석 리포트 생성)