SoundMind AI Ecosystem
본 프로젝트는 Soundmind-Labs 소속 AI Research Engineer로서 설계·구축한 AI Sales Enablement Platform입니다.
상용 소스코드 및 영업 정보는 포함되어 있지 않으며 아키텍처 설계와 기술적 의사결정 경험을 중심으로 정리했습니다.
Overview
고객 문서 기반 RAG PoC를 자동 생성·배포·시연할 수 있는 AI Sales Enablement Platform
주요 성과
- 신규 RAG 엔진 Prototype 배포 리드타임 — 2주 → 5분 (99% 이상 단축)
- MSA 규모 — 9 Projects · 161 APIs · 15+ Docker · 103+ 단위 테스트
- 최대 99개 RAG Pipeline 동시 운용 (고객사별 독립 환경 분리)
- RAG R&D — 81개 Q&A · 11개 공공문서 · 3,678페이지 대상 Node-level Ablation Study 수행
- Ablation 정량화 — Reranking −12.8%p(핵심 기여) · Query Decomposition +6.8%p(성능 저하 요인)
- 문서 분석 — Dual-LLM(Gemini + GPT-4o) 2단계 검수 파이프라인 기반 26개 특성 프로파일링 → 4차원 Decision Tree 자동 추천
- VLM 파싱 A/B 테스트 — GPT-4o Judge 가중 평균 0.888 → 1.000 (+0.113), 환각·정보 누락 해소
- PoC 납품 — DB 사업 회사 대상 8개 문서 · 34개 테스트 케이스 · Golden Path 3회 리허설 검수 완료
- 인프라 — 15+ Docker · Grafana + Loki + Promtail 실시간 모니터링 · 50명 동시 사용 대비
무엇을 하는 시스템인가
- 고객 문서를 업로드하면 Gemini 2.0 Flash 1차 분석 → GPT-4o 2차 검수의 3-Stage 파이프라인으로 문서 특성을 자동 파악
- AI가 4차원 전략 공간(Chunking 5종 · Retrieval 5종 · Indexing 4종 · Post-Processing 4종)에서 최적 RAG Pipeline을 추천·생성·배포
- 고객사 담당 영업팀은 PoC 데모를 즉시 구성하고, 고객사는 PlayGround에서 직접 체험
- 분석 → 배포 → 평가 → 모니터링까지 전 과정을 하나의 워크플로우로 자동화
- 고객사 문서 도입시 신규 엔진 Prototype 배포 리드타임 2주 → 5분 (99% 이상 단축)
규모
- 9개 프로젝트 · 161개 API · 103+ 단위 테스트
- 최대 99개 RAG Pipeline 동시 운용 (포트 9201~9299)
- 7개 파서 클래스 · 10개 확장자 지원 (PDF, DOCX, XLSX, XLS, TXT, MD, RST, JSON, HWP, HWPX)
- LLM: OpenAI · Gemini 등 클라우드 API + vLLM 기반 로컬 모델 서빙
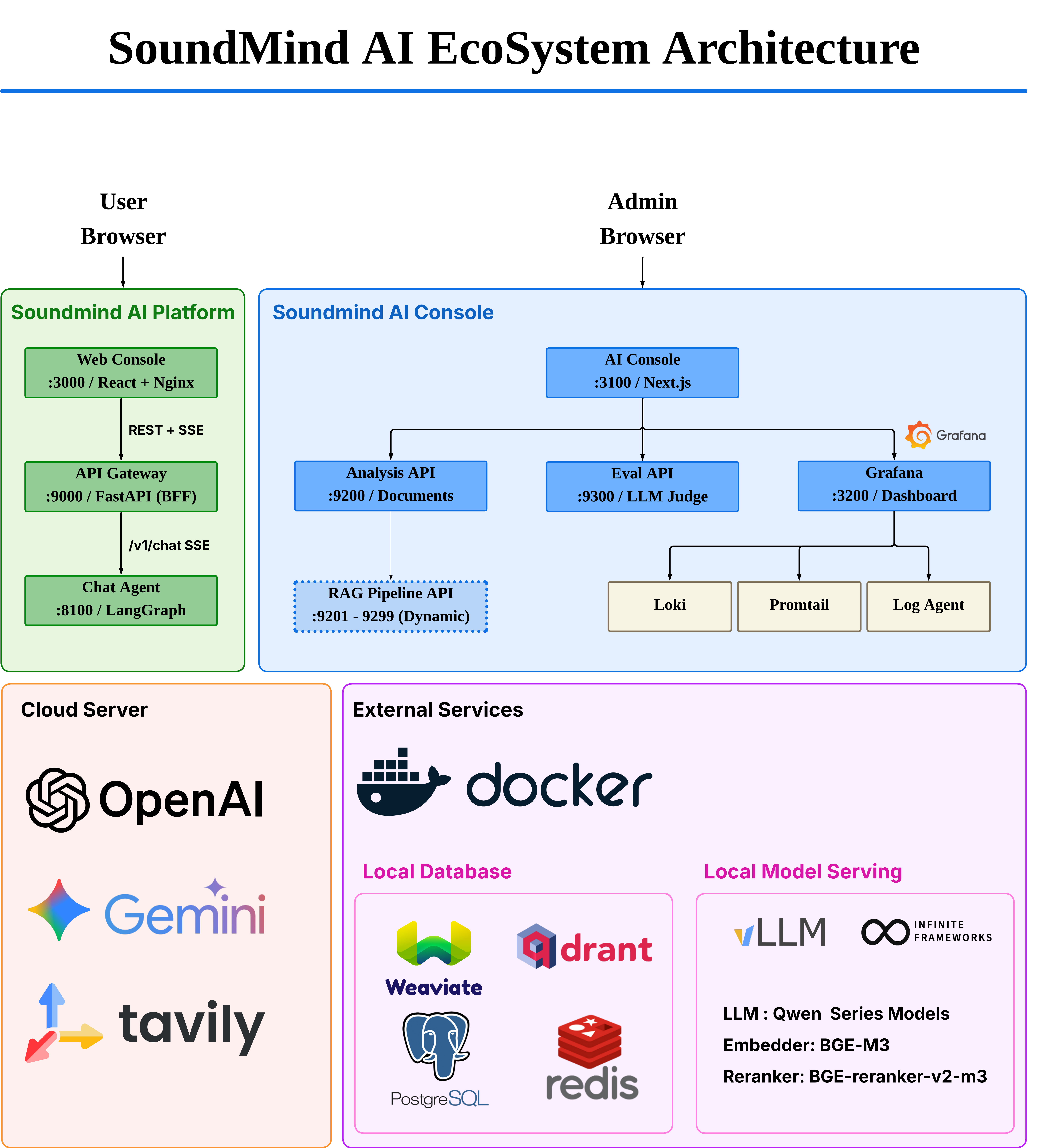
System Architecture
※ 2026.03 사운드마인드 퇴사 시점 기준 정리. 이후 본인의 추가 기여는 없음.
본 프로젝트는 단독 개발 프로젝트로서, 기획부터 디자인, 시스템 개발 및 배포까지 솔로프리너로 진행했습니다. 퇴사 시점 기준 Beta 버전으로 End User 테스트를 진행 중이었습니다.
SoundMind AI Ecosystem은 크게 3개 축으로 구성됩니다. 고객 대면 서비스(AI Platform), 내부 운영 도구(AI Console — Analysis · Eval · Monitoring), 그리고 이들이 공유하는 모델 서빙 인프라입니다.
모델 서빙 인프라:
• LLM — Qwen3 시리즈, vLLM 서빙 (OpenAI 호환 API)
• Embedder / Reranker — BGE-M3 + BGE-Reranker-v2-M3, Infinity 서빙. vLLM에서 BGE-M3 로드 시 아키텍처 호환 문제(XLMRobertaModel로 인식되어 sparse/colbert weight 누락)가 발생하여, 임베딩 모델 서빙에 특화된 Infinity로 전환
이 글의 구성:
① RAG R&D — Advanced RAG 구축 → 정량 평가 → Ablation Study → "문서마다 다른 전략이 필요하다"는 인사이트 도출
② AI Console — R&D 인사이트를 바탕으로 구축한 내부 운영 플랫폼 (Analysis · Eval · Monitoring)
③ AI Platform — 고객이 즉시 PoC를 체험할 수 있는 Playground (RAG Agent · Chat Agent · AICC Agent)
RAG R&D — 공공기관 전용 범용 RAG 고도화 여정
Advanced RAG를 구축하고 정량 평가와 Ablation Study를 거치며 "문서마다 다른 전략이 필요하다"는 핵심 인사이트를 도출한 과정입니다. 이 R&D 결과가 Analysis Platform의 4차원 Decision Tree 자동 추천 시스템에 직접 반영되었습니다.
1단계 — Advanced RAG 설계 및 구축
회사에 RAG 파이프라인이 전무한 상태에서, B2B2G(기업 → 공공기관) 사업 모델로 NLP 시장에 진출하며 Naive RAG가 아닌 Advanced RAG를 처음부터 설계하기로 결정했습니다.
모델 선정 — LLM · Embedder · Reranker:
클라우드 서버로 플랫폼을 제공하되 GPU는 On-premise 환경이었기에 Local Model 서빙이 필수였습니다. 추론 능력을 갖춘 대형 모델이 필요했고, 글로벌 벤치마크에서 높은 성능을 기록한 Qwen3 시리즈를 LLM으로 선정, vLLM으로 서빙했습니다.
Embedder와 Reranker도 Qwen 시리즈로 통일하려 했으나 vLLM에서 아키텍처 호환 문제가 발생하여 배포에 실패했고, 범용 오픈소스 모델 중 한국어 평가 지표가 가장 높았던 BGE-M3(Embedder) + BGE-Reranker-v2-M3(Reranker)를 채택, 임베딩 모델 서빙에 특화된 Infinity로 서빙했습니다.
이후 어떤 기술을 도입할 것인가를 리서칭한 뒤, 세 가지 핵심 컴포넌트를 선정했습니다.
Query Expansion (Rewrite + Decomposition):
B2B2G 사업 특성상 End User의 도메인을 특정할 수 없지만, 고객이 정부기관이라는 것은 알 수 있었습니다. 공공문서는 정확도가 생명이므로, 동일한 질문을 다양하게 재작성(Rewrite)하여 관련 컨텍스트를 빠짐없이 확보하고, 복합 질의는 서브쿼리로 분해(Decomposition)하여 다중 관점의 정보를 수집하는 전략을 채택했습니다.
Hybrid Search (Dense + Sparse + RRF):
정부문서에는 한자어, 공공기관 전용 용어 등 키워드 매칭이 중요한 어휘가 많아 Sparse Search(BM25)가 유효할 것으로 판단했습니다. Dense와 Sparse 검색을 조합하는 RRF 알고리즘을 활용하되, 당시 알고리즘 구현 경험이 부족했기에 Hybrid Search를 네이티브로 지원하는 Weaviate를 VectorDB로 도입했습니다. 이후 Flat 구조 문서에서는 메타데이터 필터링 기반 검색이 더 효과적임을 확인하여 Qdrant(Filter 기반)를 추가, 문서 복잡도에 따라 VectorDB를 이원화 설계했습니다.
Reranking (Top-k=5):
BGE-Reranker-v2-M3는 범용 모델 중 한국어 평가 지표가 가장 높았고, 오픈소스 라이센스로 On-premise 배포에 제약이 없어 선택했습니다.
Data Parsing 확장:
초기에는 Docling을 사용했으나 문서 파싱 레이턴시가 지나치게 높아 실용성이 떨어졌고, pdfplumber + PaddleOCR로 교체하여 처리 속도를 확보했습니다. 이후 정부기관 특수 목적상 HWP·HWPX 문서가 다수 존재했고 DOCX, XLSX 등 다양한 포맷도 필요하여, 확장자별 개별 OSS 파서들을 통합한 UnifiedFileParser(7개 파서 클래스 · 10개 확장자)를 구축했습니다.
• PDFParser (.pdf) — 3단계 Fallback 체인: pymupdf4llm(1차, 레이아웃 인식 Markdown 추출) → pdfplumber(2차 fallback) → PaddleOCR(3차, 한국어 스캔 문서 OCR). 페이지당 텍스트 50자 미만이면 스캔 PDF로 판단하여 자동 OCR 전환
• DOCXParser (.docx) — python-docx 기반 단락 + 표 추출, 문서 속성 포함
• XLSXParser (.xlsx, .xls) — openpyxl (read_only=True, data_only=True), 전체 시트 순회 및 시트별 구조화
• TXTParser (.txt, .md, .rst) — Built-in, 인코딩 자동 감지 (UTF-8 → CP949 → EUC-KR → Latin-1 순서 시도)
• JSONParser (.json) — Built-in json 모듈, JSON 계층 구조를 사람 읽기용 텍스트로 변환
• HWPParser (.hwp) — olefile 기반 OLE compound document 파싱, BodyText 섹션에서 HWPTAG_PARA_TEXT(tag=67) 레코드 추출 + zlib 해제
• HWPXParser (.hwpx) — zipfile + BeautifulSoup 기반 OOXML 파싱, Contents/section*.xml에서 텍스트 추출
Embedding 서빙 프레임워크 벤치마크 — vLLM vs Infinity
vLLM에서의 아키텍처 호환 문제로 Infinity를 선택한 후, 10개 PDF(arxiv 5 + 한국 공공문서 5), 각 20회 반복 측정으로 두 프레임워크의 임베딩 서빙 성능을 정량 비교했습니다. "호환 문제로 전환했다"에 그치지 않고, 다양한 도메인·언어의 문서에서 워크로드 특성별 최적 프레임워크를 규명하여 인프라 설계 근거를 확보했습니다.
Online Serving — 단일 요청 Latency & 동시 요청 Throughput (mean ± std):
| 텍스트 길이 | vLLM Latency | Infinity Latency | vLLM req/s (c=16) | Infinity req/s (c=16) |
|---|---|---|---|---|
| Short (~100자) | 13.0 ± 0.4ms | 19.9 ± 0.3ms | 260 ± 29 | 155 ± 5 |
| Medium (~500자) | 15.0 ± 1.6ms | 20.8 ± 0.5ms | 213 ± 9 | 150 ± 7 |
| Long (~1000자) | 18.4 ± 3.6ms | 20.9 ± 0.7ms | 202 ± 10 | 149 ± 6 |
→ vLLM이 12~34% 낮은 latency, 1.4~1.7배 높은 req/s. 단, Infinity는 std가 현저히 작아(0.3~0.7ms vs 0.4~3.6ms) 문서 유형에 무관한 일관된 응답 시간을 보장 — P99와 mean의 차이가 작아 SLA 예측이 용이하며, 프로덕션 RAG 파이프라인에서 안정적 운용에 유리
Batch Processing — 배치 Throughput (batch=32, K tokens/s, mean ± std):
| 텍스트 길이 | vLLM (K tokens/s) | Infinity (K tokens/s) | 배율 |
|---|---|---|---|
| Short (~100자) | 28 ± 4 | 39 ± 2 | Infinity 1.4x |
| Medium (~500자) | 98 ± 25 | 167 ± 18 | Infinity 1.7x |
| Long (~1000자) | 154 ± 28 | 255 ± 48 | Infinity 1.7x |
→ Infinity가 1.4~1.7배 높은 tokens/s — 고정 배치를 한 번에 forward pass하여 GPU 활용률 극대화. Long text 최대 323K tokens/s 도달
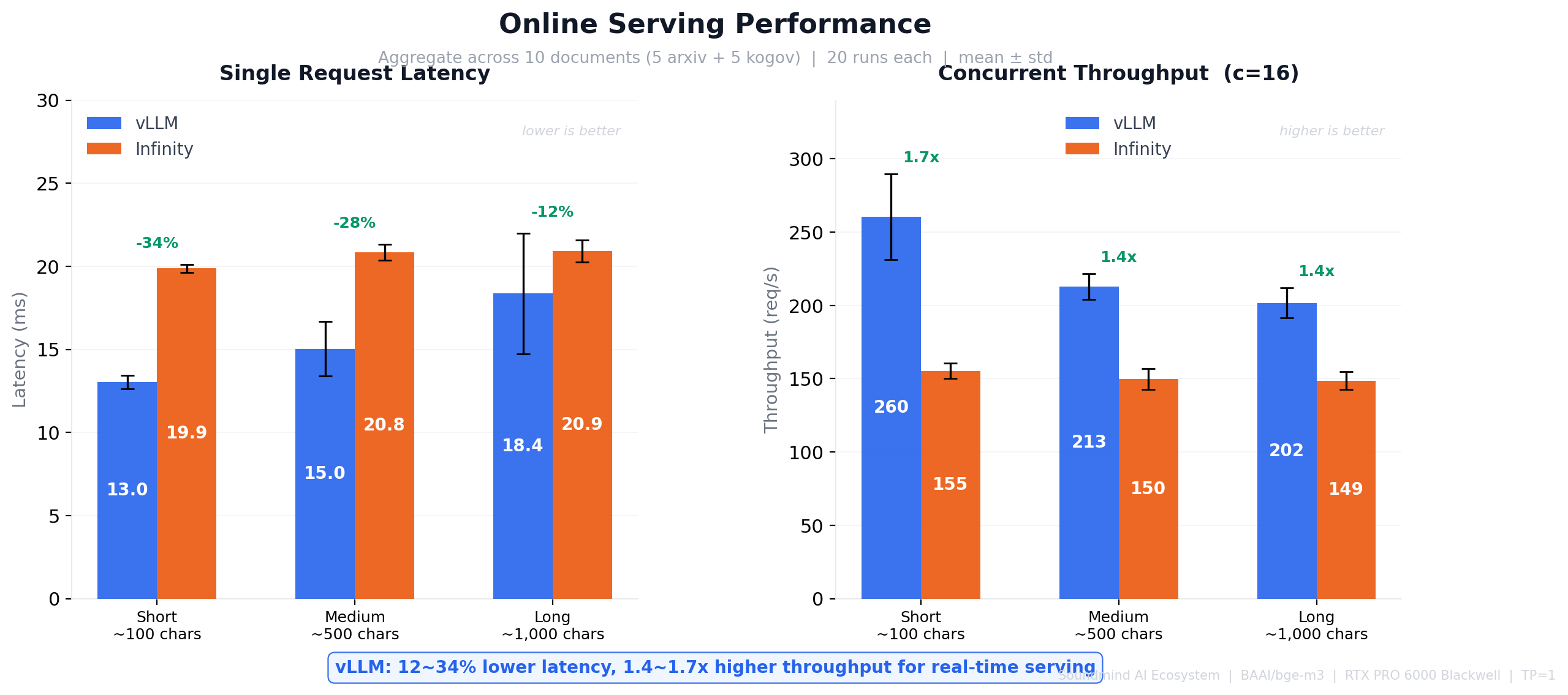 1. Online Serving — vLLM이 12~34% 낮은 latency, 1.4~1.7x 높은 req/s
1. Online Serving — vLLM이 12~34% 낮은 latency, 1.4~1.7x 높은 req/s
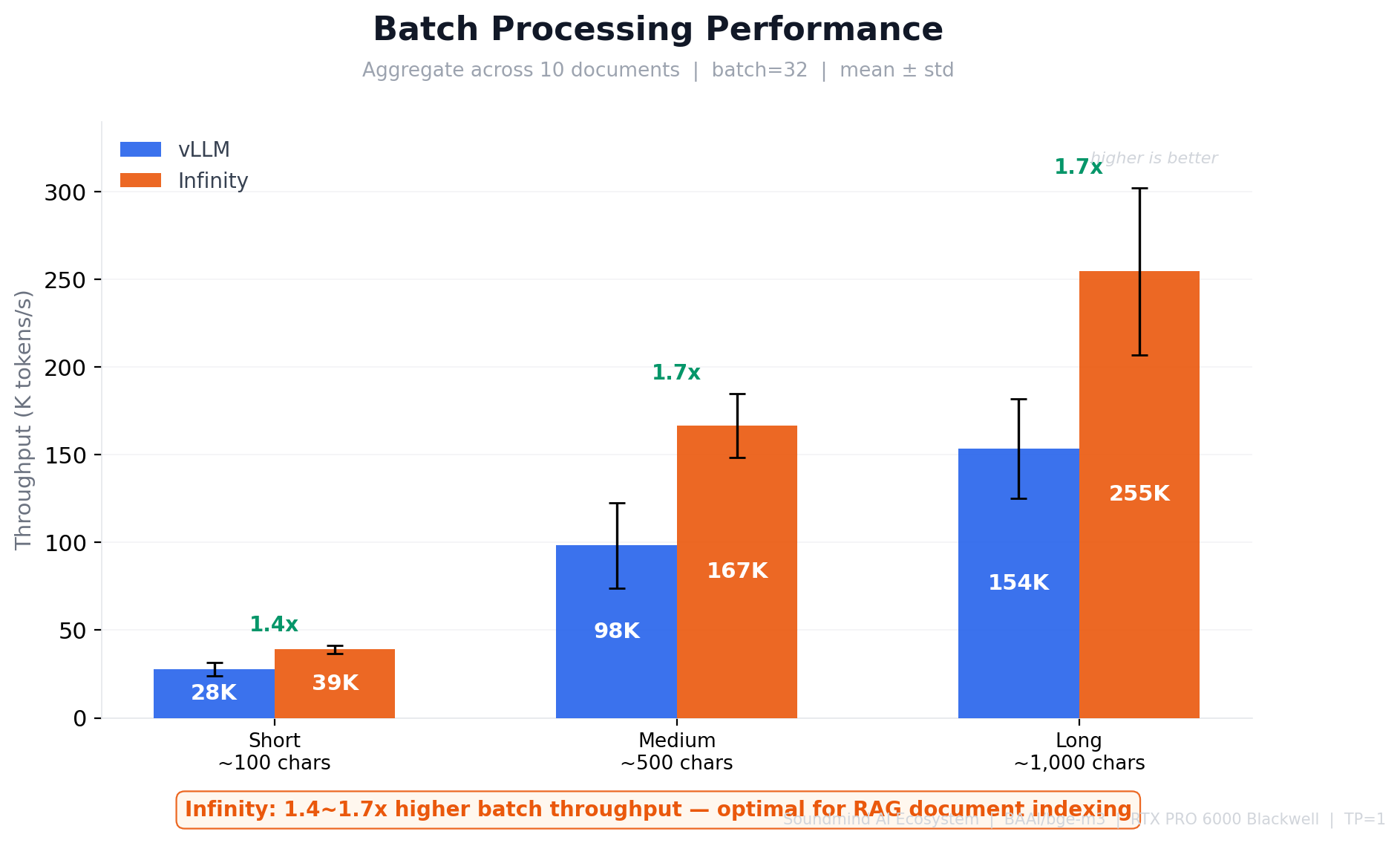 2. Batch Processing — Infinity가 1.4~1.7x 높은 tokens/s (RAG 문서 인덱싱 최적)
2. Batch Processing — Infinity가 1.4~1.7x 높은 tokens/s (RAG 문서 인덱싱 최적)
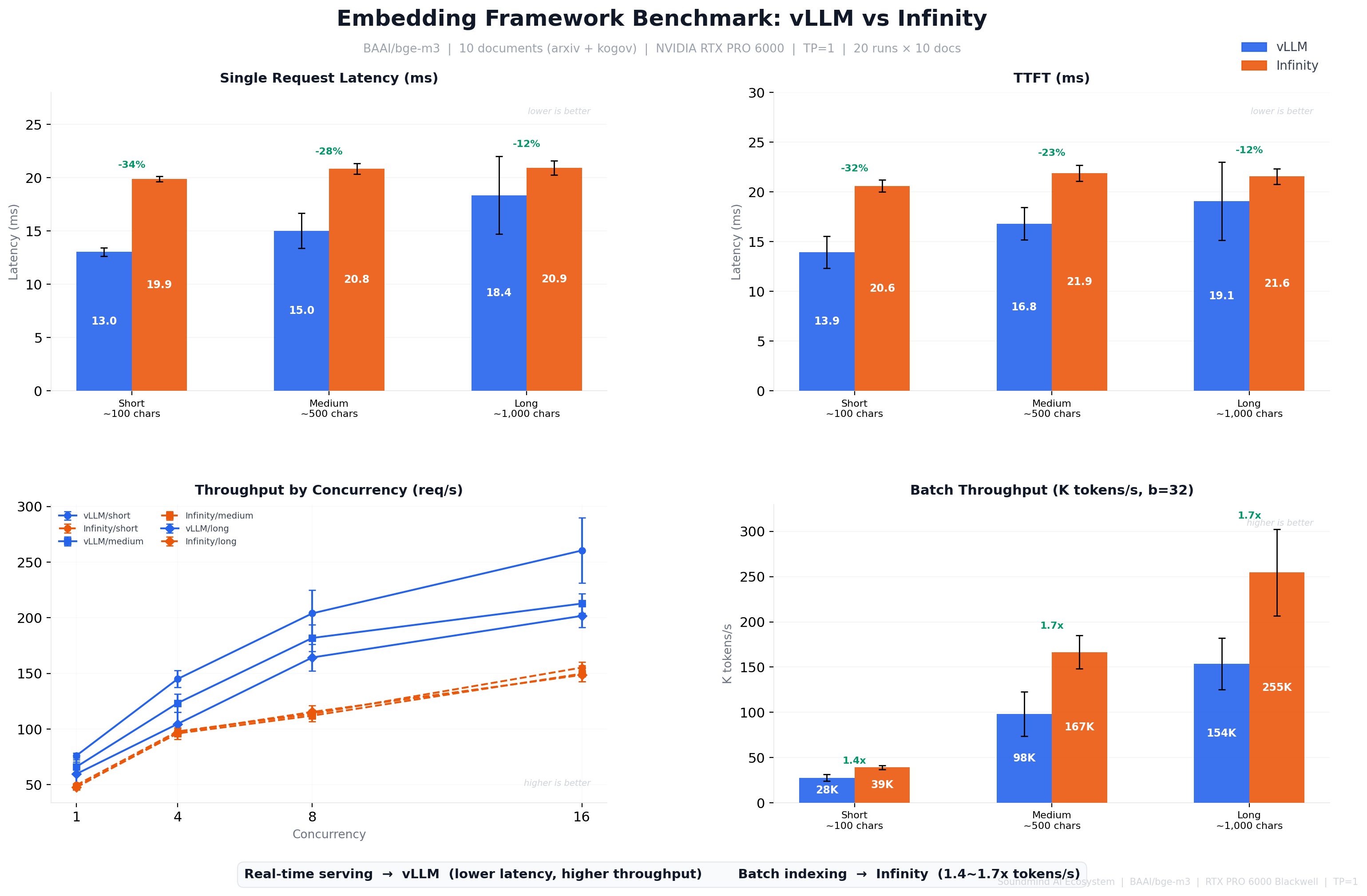 3. 종합 벤치마크 — Real-time serving → vLLM, Batch indexing → Infinity (10 docs × 20 runs)
3. 종합 벤치마크 — Real-time serving → vLLM, Batch indexing → Infinity (10 docs × 20 runs)
운영 관점 결론:
| 워크로드 | 특성 | 최적 프레임워크 |
|---|---|---|
| 문서 업로드 → 대량 임베딩 인덱싱 | 수백~수천 청크 배치, latency 덜 민감 | Infinity ✓ |
| 사용자 쿼리 → 실시간 검색 | 단건 요청, latency 민감 | vLLM |
Trade-Off 의사결정:
단건 요청 latency에서는 vLLM이 우위지만, 우리 사업 모델은 다수의 정부기관을 동시에 수용해야 했습니다. 고객사가 추가될 때마다 수백~수천 페이지의 공공문서가 업로드되고, 이를 청크 단위로 대량 임베딩하여 인덱싱하는 것이 핵심 워크로드였습니다. 단건 쿼리 응답 속도(ms 단위 차이)보다 대규모 문서 인덱싱 처리량이 서비스 확장성을 좌우하는 병목이었기에, 배치 throughput에서 1.4~1.7배 우위를 보이는 Infinity를 선택했습니다. 부가적으로 Infinity는 입력 문서 유형에 무관한 일관된 응답 시간(low variance)을 보여, 배치 처리 성능과 운영 안정성 양면에서 RAG 파이프라인에 적합했습니다. 10개 문서(영어 arxiv + 한국어 공공문서) × 20회 반복에서 크로스오버 패턴이 일관 재현되어, 이 Trade-Off가 도메인·언어에 무관하게 유효함을 확인했습니다.
2단계 — 정량 평가에서 드러난 문제
Advanced RAG를 구축한 뒤, 성능을 정량적으로 측정하기 위해 RAGAS 기반 평가 프레임워크를 직접 구축했습니다.
LLM 기반 Silver Dataset 자동 생성:
데이터 엔지니어링의 Medallion Architecture(Bronze → Silver → Gold) 패턴을 평가 데이터 생성에 차용했습니다. 3,678페이지의 Raw 공공문서(Bronze)에서 Qwen3-VL-30B가 난이도·질의 유형·추론 홉 수가 태깅된 81개 Q&A Ground Truth(Silver)를 자동 생성했습니다. 이 Silver 데이터셋으로 Node-level Ablation Study를 수행하여 컴포넌트별 기여도를 정량화(Gold)하고, 그 결과가 AI Console 자동 추천 엔진의 Decision Tree 임계값에 직접 반영되었습니다.
RAGAS 평가의 한계:
RAGAS 프레임워크로 평가를 수행했으나, RAGAS의 핵심 메트릭인 ROUGE-L(0.050) / BLEU(0.002) 등은 Ground Truth와 RAG 응답 간의 토큰 단위 일치도(CER, WER 등)를 기반으로 점수를 산출합니다.
그러나 생성형 AI는 동일한 맥락이라도 매번 다른 어휘와 문장 구조로 답변을 생성하기 때문에, 의미적으로 정확한 응답도 토큰이 다르면 낮은 점수가 나올 수밖에 없었습니다. 한국어의 교착어 특성(조사·어미 변형)이 이 문제를 더욱 심화시켰습니다.
이를 계기로 토큰 매칭이 아닌 의미 단위로 응답 품질을 판단하는 LLM-as-a-Judge 기반 5차원 가중 평가로 전환했습니다.
노드 단위 핵심 실험 결과:
| 실험 | 비교 | 결과 | 비고 |
|---|---|---|---|
| 청킹 | Recursive vs Semantic | 600배 빠름 | → Recursive 채택 (14ms vs 8,437ms, 커버리지 유사하나 속도 압도적) |
| 검색 | Dense vs Hybrid | MRR +2.3%p | → 문서별 분기 필요 (Dense가 한국어에서 우위이나 키워드 매칭이 중요한 문서도 존재) |
| 리랭킹 | 적용 vs 미적용 | MRR +3.9%p | → 상시 활성화 (지연시간 2.8배 증가에도 정밀도 향상이 더 중요) |
다수 평가를 통해 드러난 구조적 한계:
실제 질의의 대부분은 Multi-Hop이 아닌 Flat 구조였지만, 수십 개의 컨텍스트를 한꺼번에 수집해야만 답변을 생성할 수 있는 패턴이 지배적이었습니다.
예를 들어 "20개 분과에 대한 사업 기준을 설명하라"는 질의는 20개 이상의 컨텍스트가 필요한데, Reranker의 Top-k=5로는 턱없이 부족했습니다. 이런 유형의 문서를 분석해보면, 대부분 섹션의 결론이나 요구사항 같은 반복적인 구조를 가지고 있었습니다.
이 인사이트에서 Qdrant 도입의 근거가 나왔습니다. 반복 구조 문서는 시맨틱 검색보다 JSON 메타데이터 기반 Filter 검색이 더 효과적이었고, 문서를 업로드할 때 섹션별 메타데이터를 구조화하여 저장하면 필요한 20개 이상의 컨텍스트를 정확하게 필터링할 수 있었습니다. Weaviate(Hybrid Search)와 Qdrant(Filter 기반)를 문서 특성에 따라 분기하는 VectorDB 이원화 설계가 이 경험에서 비롯되었습니다.
E2E 종합 평가 결과 — Advanced RAG가 오히려 낮았다:
81개 Q&A 전수 평가, 5차원 가중 평균 기준:
| Metric | 가중치 | Naive RAG | Advanced RAG | 차이 |
|---|---|---|---|---|
| Faithfulness | 30% | 0.813 | 0.738 | −7.5%p |
| Relevance | 25% | 0.825 | 0.763 | −6.2%p |
| Completeness | 20% | 0.813 | 0.688 | −12.5%p |
| Coherence | 15% | 0.925 | 0.938 | +1.3%p |
| Fluency | 10% | 0.963 | 0.950 | −1.3%p |
| 가중 평균 | 100% | 0.848 | 0.785 | −6.3%p |
Completeness가 −12.5%p 급락하여, 정보를 빠짐없이 담아야 하는 공공문서 Q&A에서 치명적인 약점을 드러냈습니다.
"모든 컴포넌트를 추가하면 좋아질 것"이라는 가정이 틀렸음을 인정해야 했습니다.
이 경험이 "문서 특성에 맞는 맞춤형 RAG 구조가 필요하다"는 핵심 인사이트로 이어졌고, 문서별로 최적화된 파이프라인을 자동 생성하는 플랫폼을 만드는 것을 목표로 설정하게 되었습니다.
3단계 — "왜 안 되는가" 규명: Ablation Study
E2E 메트릭으로는 "어디가 문제인지" 알 수 없었습니다. Advanced RAG가 Naive보다 오히려 낮은 점수를 기록했지만, 4개 추가 컴포넌트 중 어느 것이 범인인지는 E2E만으로 특정할 수 없었습니다. 그래서 노드 단위 Ablation Study를 직접 설계·수행했습니다.
핵심 발견:
• Reranking 제거 시 −12.8%p — 가장 임팩트 큰 핵심 컴포넌트
• Query Decomposition 제거 시 +6.8%p, 레이턴시 32% 감소(129s→88s) — 오히려 성능을 깎고 있었음
• Query Rewrite 제거 시 −0.8%p — 기여도 미미
• Hybrid → Dense 전환 시 −5.0%p — 중간 수준 기여
| 제거한 컴포넌트 | 성능 변화 | 레이턴시 | 판정 |
|---|---|---|---|
| Reranking | −12.8%p | — | → 상시 활성화 (제거 시 성능 급락, 핵심 기여 요인) |
| Query Decomposition | +6.8%p | 32%↓ (129s→88s) | → 조건부 활성화 (제거하니 오히려 성능 향상) |
| Query Rewrite | −0.8%p | — | → 유지 (기여도 미미하나 제거 시 소폭 하락) |
| Hybrid → Dense | −5.0%p | — | → 문서별 분기 (Dense 우위 문서와 Hybrid 필요 문서 공존) |
Query Decomposition이 해로웠던 이유:
서브쿼리로 분해하는 과정에서 원래 질의의 핵심 의도가 희석되고, 각 서브쿼리가 가져오는 컨텍스트에 노이즈가 유입되어 오히려 답변 품질이 하락했습니다. Ground Truth의 80%가 Easy/Medium 난이도여서, 복잡한 추론 없이도 단일 질의로 충분히 답변 가능한 케이스가 대부분이었던 점도 영향을 미쳤습니다.
Hybrid Search가 Dense 대비 떨어진 이유:
한국어 공공문서에서 BM25의 키워드 매칭 정확도가 낮았습니다. 한국어는 조사·어미 변형이 많아 동일 키워드도 형태가 달라지고, 공공문서 특유의 한자어·축약어가 토크나이저와 잘 맞지 않아 Sparse 검색이 노이즈를 유입시켰습니다(Sparse 비중이 높을수록 MRR 하락: α=0.7→0.838, α=0.3→0.811). 다만 법률·규정 문서처럼 정확한 용어 매칭이 중요한 도메인에서는 Hybrid가 여전히 유효했기에, 문서 특성에 따른 분기 설계로 이어졌습니다.
핵심 인사이트:
E2E 평가만으로는 "Advanced가 성능이 더 낮다"는 알 수 있지만, "Query Decomposition이 범인이다"는 알 수 없었습니다. Reranking의 +12.8%p 기여가 Query Decomposition의 −6.8%p 손해에 상쇄되고 있었고, 이를 분리해낸 것이 Node-level Ablation이었습니다.
4단계 — 인사이트 → Ecosystem 설계
"문서마다 다른 전략이 필요하다"가 R&D의 핵심 결론이었습니다.
• Reranking은 항상 켜야 합니다 → 전 파이프라인 Reranker 상시 활성화
• Query Decomposition은 multi-hop 질의가 예상될 때만 → 조건부 활성화 (multi_hop_likelihood > 0.4)
• 한국어 문서에서 BM25 성능 저하 → semantic_importance에 따라 Dense/Hybrid 분기
• 문서 구조에 따라 최적 청킹이 다릅니다 → 구조 복잡도 기반 청킹 전략 분기
추가 인사이트 — Data 구조화가 답변 품질을 결정합니다:
Ablation Study를 진행하면서 또 하나의 핵심 인사이트를 얻었습니다. 문서의 Data 구조화 품질이 Semantic Chunking에 영향을 미치고, 그것이 검색 결과에 영향을 미쳐, 결국 최종 답변 생성 품질까지 연쇄적으로 결정한다는 것이었습니다. 특히 공공문서의 복잡한 표·차트·레이아웃이 텍스트 기반 파서로는 구조가 소실되어 청킹·검색·생성 전 단계에서 품질 저하를 유발했습니다.
이 인사이트가 VLM(Vision-Language Model) 기반 문서 파싱 연구로 이어졌고, 별도 프로젝트 WigtnOCR(Qwen3-VL-2B를 LoRA fine-tuning하여, 비교 실험 4개 모델 중 Table TEDS 1위 달성)을 시작하게 되었습니다.
사업 배경 — 왜 "플랫폼"이어야 했는가:
우리 회사는 음성 AI 전문 회사였고, NLP 사업 진출은 처음이었습니다. 보여줄 수 있는 PoC가 없는 상태에서 네트워크 기반으로 고객사 시연 기회를 만들어야 했는데, 매번 "2주의 PoC 기간을 주세요, 데이터를 주세요"라고 요청하는 것은 영업팀에게 현실적으로 어려운 일이었습니다.
기회가 생겼을 때 영업팀이 즉시 클라우드 서버에 접속하여 고객 문서를 업로드하고 바로 시연할 수 있는 환경이 필요했습니다.
이 필요와 R&D 인사이트가 결합되어, 문서 분석 → 맞춤형 파이프라인 자동 생성 → 원클릭 배포를 비개발자도 운용 가능한 플랫폼 콘솔로 구축하기로 결정했습니다.
여기에 배포된 파이프라인의 품질을 바로 확인할 수 있는 평가 기능, 운영 상태를 실시간으로 파악하는 모니터링·로그 분석, 사용자·권한을 관리하는 Admin 기능까지 하나의 콘솔에 통합 설계하여, 지금의 SoundMind AI Ecosystem 아키텍처가 완성되었습니다.
AI Console — 내부 운영 플랫폼
RAG R&D 인사이트와 사업 요구가 결합되어 탄생한 비개발자 운용 가능한 통합 Admin 콘솔입니다. Next.js 기반 단일 웹 콘솔(:3100)에서 문서 분석·배포(Analysis), 품질 평가(Eval), 실시간 모니터링(Monitoring), 인프라·사용자 관리(Admin)까지 RAG 영업 사이클 전체를 운용합니다.
 1. Login — AI Console 관리자 인증 화면
1. Login — AI Console 관리자 인증 화면
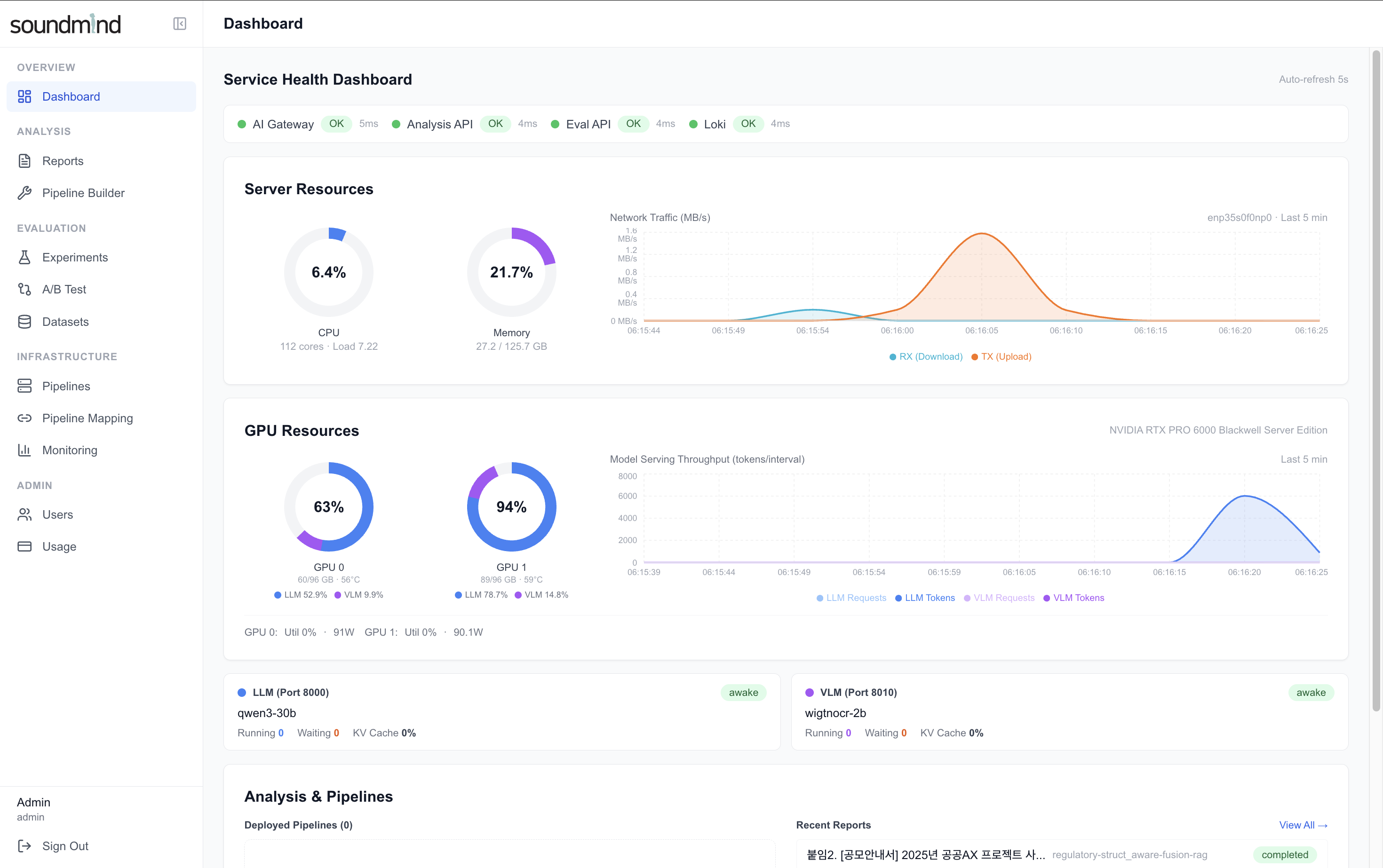 2. Dashboard — 서비스 상태, GPU 할당, 모델 서빙 현황, Pipeline 관리
2. Dashboard — 서비스 상태, GPU 할당, 모델 서빙 현황, Pipeline 관리
AI Console — Analysis (문서 분석 → RAG 자동 배포)
고객 문서를 업로드하면 AI가 문서 특성을 다각도로 분석하고, 최적의 RAG Pipeline을 추천한 뒤 원클릭으로 Docker 컨테이너를 배포합니다. 신규 엔진 Prototype 배포 리드타임 2주 → 5분 (99% 이상 단축).
2-Tier 아키텍처: Analysis API(포트 9200, Control Plane) + 배포된 파이프라인(포트 9201~9299, Data Plane)
설계 배경 — 왜 Dual-LLM 2단계 검수인가
단일 LLM으로 26개 특성을 분석하면, 해당 모델의 학습 편향이 결과에 그대로 반영됩니다.
문서 구조 복잡도나 도메인 특화도 같은 판단은 모델마다 기준이 다르기 때문에, 하나의 모델만 신뢰하면 특정 문서 유형에서 과잉/과소 설계가 발생할 수 있습니다.
• Gemini 2.0 Flash — PDF File API로 네이티브 분석, 1차 프로파일링 + 전략 추천 담당. Flash 모델로 비용 효율적인 대량 분석에 적합
• GPT-4o — Gemini의 분석 결과를 2차 검수. OSS 파서(pdfplumber)로 추출한 원문 텍스트와 Gemini 프로파일을 함께 검토하여, Structured Outputs(json_schema strict mode)로 프로파일 정확성과 전략 적합성을 검증하고 confidence 보정. 불일치 시 GPT-4o의 판단을 우선 적용
두 모델이 동일 입력을 독립 평가하는 교차 검증이 아니라, Gemini가 분석하고 GPT-4o가 검수하는 순차적 2단계 파이프라인입니다. GPT-4o는 Gemini가 접근할 수 없는 OSS 파서 추출 텍스트까지 비교할 수 있어 검수자로서 비교 우위를 가집니다.
문서 분석 기준 — 26개 특성 프로파일링
문서 분석 기준은 urstory-rag(한국어 최적화 프로덕션 RAG 오픈소스)의 한국어 RAG 전략 설계를 참고하여, 공공기관 문서 특성에 맞게 4개 프로파일 · 26개 특성으로 확장 설계했습니다.
- 구조 프로파일 — 계층 깊이(1~4+), 섹션 독립성(0.0~1.0), 교차 참조 밀도, 지배적 구조 유형(서술형/표 중심/계층/혼합/QA), 반복 패턴
- 콘텐츠 프로파일 — 정보 밀도(sparse/moderate/dense), 밀도 분포, 엔티티 관계 구조, 도메인 특화도(0.0~1.0)
- 검색 프로파일 — 예상 질의 유형(factual/comparative/aggregation/causal/procedural), 키워드·시맨틱 중요도, 컨텍스트 윈도우 필요량, 다중 홉 가능성
- 시각 프로파일 — 표 복잡도(none~nested), 차트 존재 여부, 이미지 정보 밀도, 레이아웃 복잡도
Stage 1 — Gemini 2.0 Flash + 텍스트 추출 (병렬)
Gemini가 PDF File API로 문서를 네이티브 분석하여 26개 특성 프로파일과 RAG 전략을 직접 추천합니다(Structured Output, temp=0.1). 동시에 pdfplumber가 텍스트를 추출하여 GPT 검증용 원문을 준비합니다. asyncio.gather로 병렬 실행하여 분석 시간을 절반으로 단축. 300페이지/50MB 초과 시 대표 페이지 샘플링(앞 60%·중간 20%·끝 20%) 자동 적용.
Stage 2 — GPT-4o 2차 검수
GPT-4o가 Gemini의 프로파일 정확성(구조 깊이, 도메인 특화도 등)과 전략 적합성(과잉/과소 설계 여부)을 json_schema strict mode로 검증합니다. confidence adjustment −0.3 ~ +0.2로 신뢰도를 보정하며, 결과는 "confirmed" / "modified" / "rejected" 3단계로 분류. GPT 미설정 시 Gemini 단독 결과에 ×0.8 페널티를 적용하여 안정성 확보.
Stage 3 — Strategy Engine + 동적 파이프라인 조립
ReportGenerator가 Gemini 원본 + GPT 수정사항을 병합한 뒤, 4차원 전략 공간(Chunking 5종 · Retrieval 5종 · Indexing 4종 · Post-Processing 4종, 이론적 조합 6,400+)에서 최적 조합을 결정합니다.
Ablation Study 결과와 도메인 휴리스틱을 결합한 분기 로직:
• Reranking → 모든 후처리 전략에서 상시 활성화 (Ablation: 제거 시 −12.8%p)
• Query Decomposition → multi_hop_likelihood > 0.4일 때만 활성화 (Ablation: 무조건 적용 시 +6.8%p 성능 저하. 0.4 임계값은 "단일 컨텍스트로 답변 불가능한 질의가 예상되는 최소 지점"으로 설정한 도메인 휴리스틱이며, 0.4/0.5/0.6 3단계 분기로 중간 복잡도는 Multi-Query, 고복잡도는 Graph-Enhanced로 전환)
• Retrieval → semantic_importance > 0.7이면 Dense, keyword_importance > 0.6이면 Hybrid (Ablation: 한국어 BM25 성능 저하 확인. 임계값은 도메인 규칙 기반 설계)
• VectorDB → metadata_filtered 전략 시 Qdrant, 나머지 Weaviate 자동 결정
DynamicRAGPipeline이 ComponentRegistry + LangGraph StateGraph를 런타임에 동적 조립. 6가지 그래프 토폴로지: Linear, Classify-Filter, Hierarchical, Multi-Index, Graph-Enhanced, Agentic.
원클릭 배포
- Jinja2 템플릿 기반 Docker Compose 자동 생성 → 원클릭 배포
- asyncio.Lock 동시성 보호 + 포트 자동 할당 (9201~9299)
- 독립 컨테이너로 격리된 RAG Pipeline 자동 생성 및 서비스 등록
- Pipeline Factory: 전략 조합에 따라 파이프라인 이름 자동 생성 (예: regulatory-struct_aware-filtered-rag)
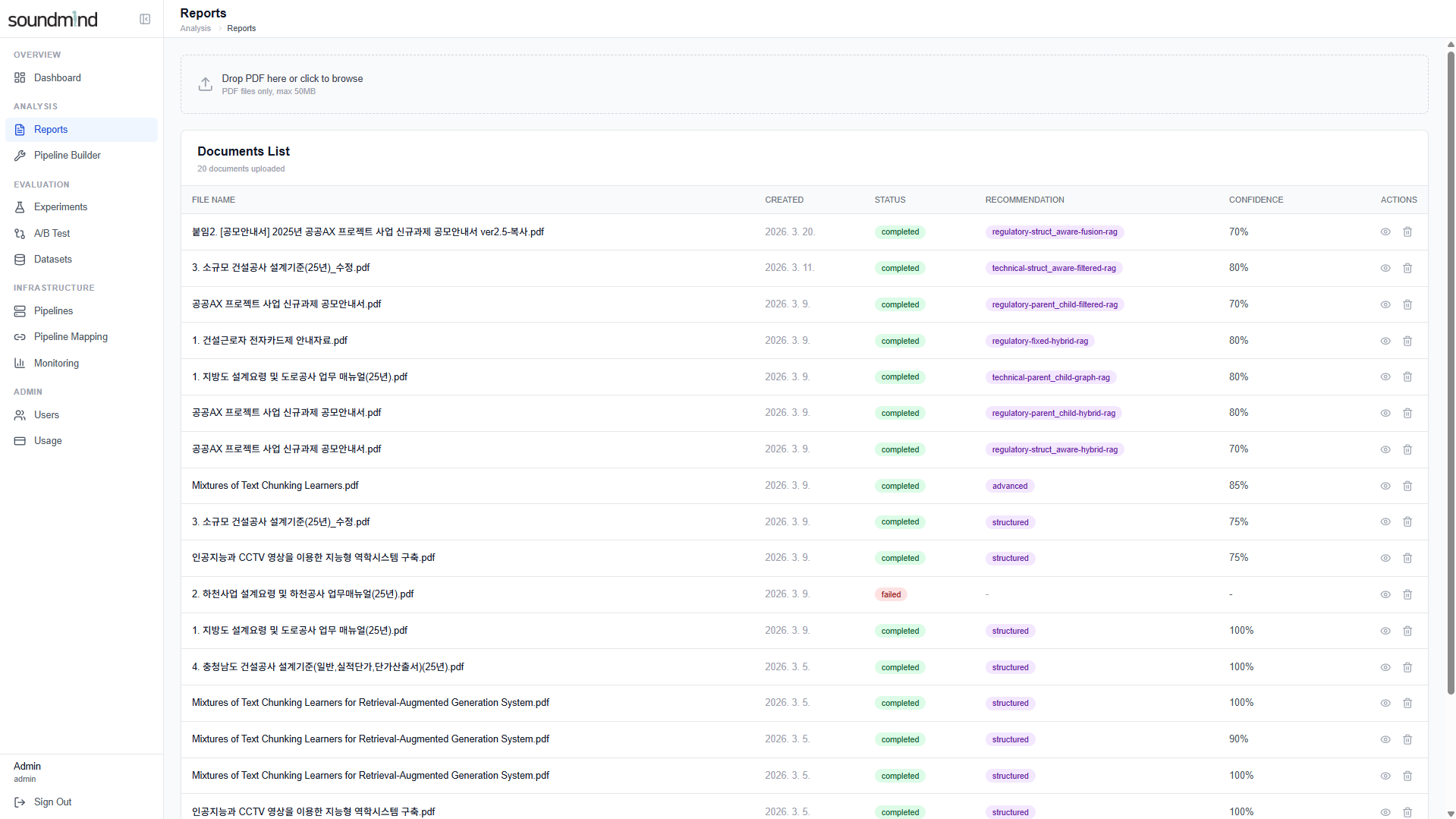 1. Reports — 문서 업로드 및 분석 결과 목록 (파이프라인 추천 · Confidence 표시)
1. Reports — 문서 업로드 및 분석 결과 목록 (파이프라인 추천 · Confidence 표시)
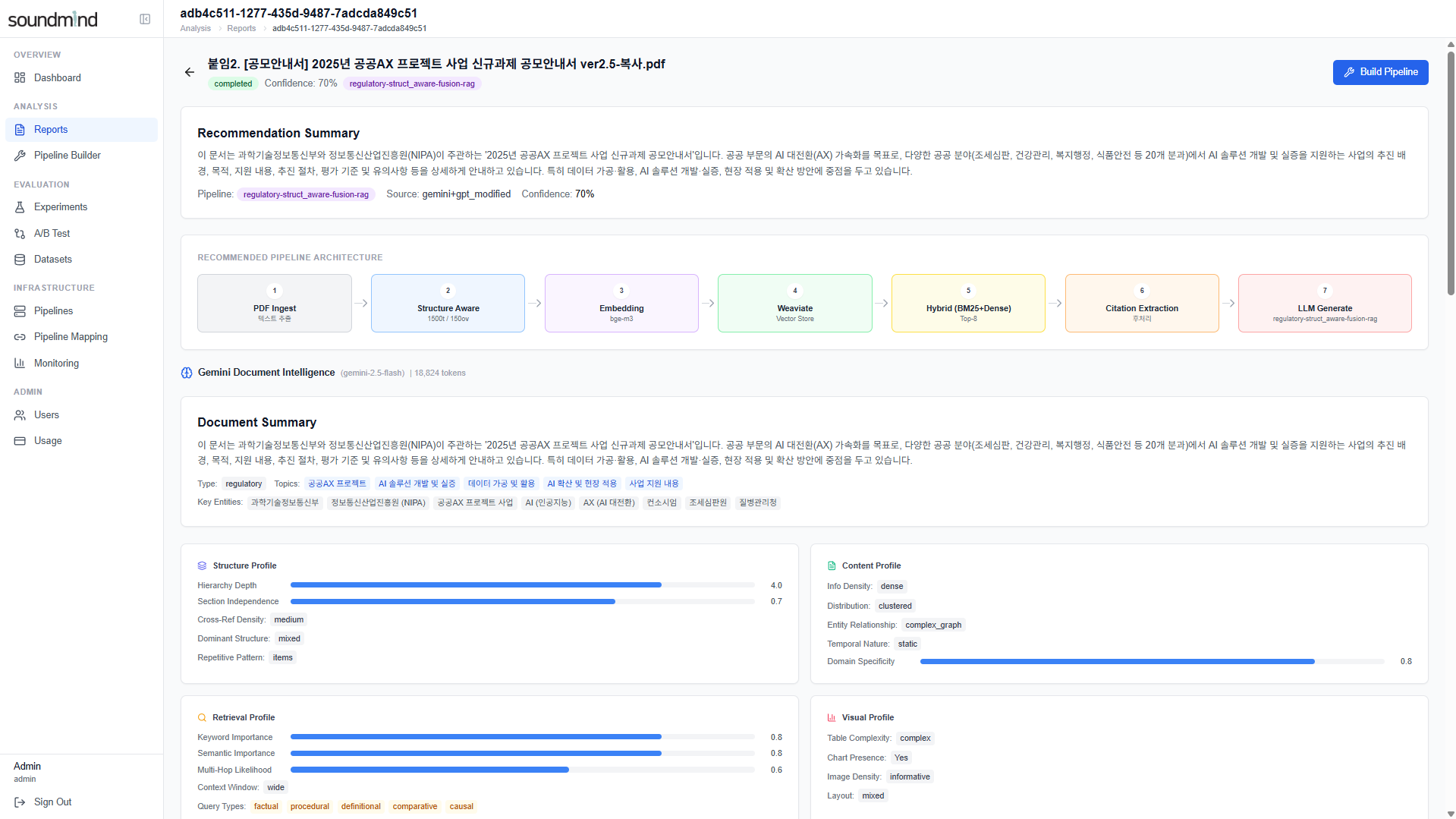 2. 전략 추천 — Recommended Pipeline Architecture + 4개 프로파일 · 26개 특성 시각화
2. 전략 추천 — Recommended Pipeline Architecture + 4개 프로파일 · 26개 특성 시각화
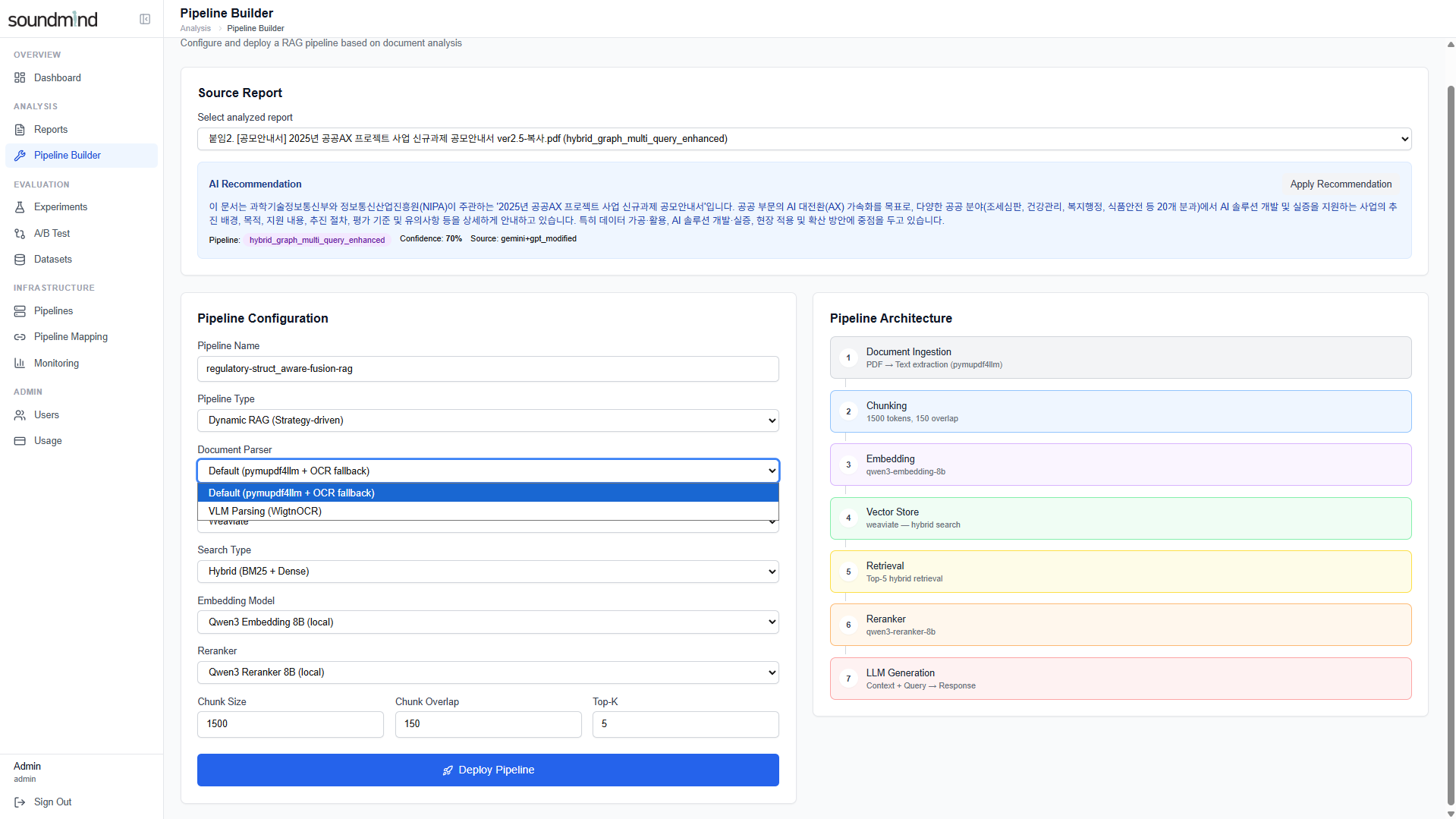 3. Pipeline Builder — AI 추천 기반 설정 조정 + VLM Parsing(WigtnOCR) 선택 + 원클릭 배포
3. Pipeline Builder — AI 추천 기반 설정 조정 + VLM Parsing(WigtnOCR) 선택 + 원클릭 배포
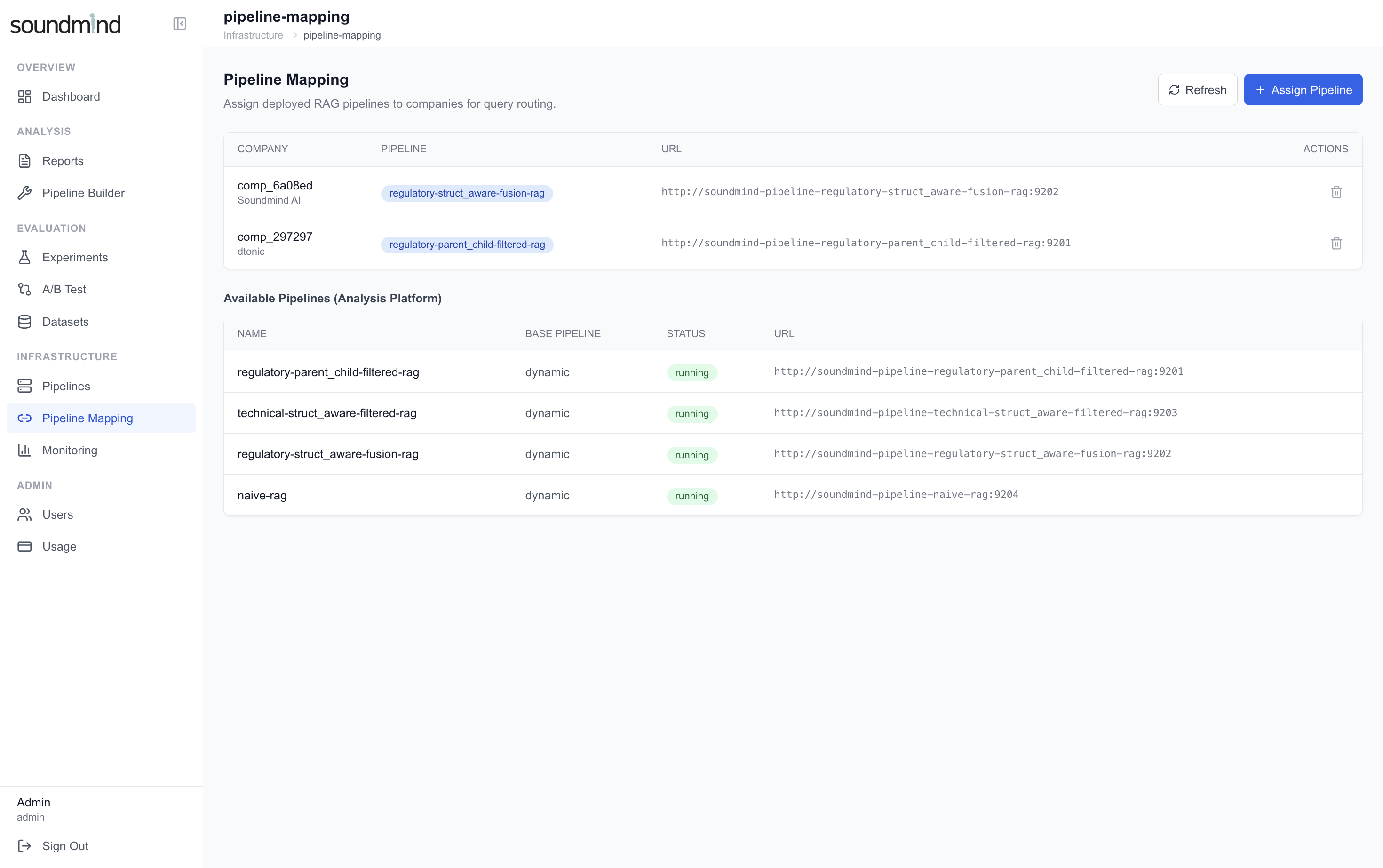 4. 배포 완료 — Docker 컨테이너 자동 생성 및 서비스 등록 완료
4. 배포 완료 — Docker 컨테이너 자동 생성 및 서비스 등록 완료
AI Console — Eval (RAG 품질 평가)
배포된 RAG Pipeline의 응답 품질을 정량적으로 평가하고, 전략 변경 전후의 효과를 통계적으로 검증합니다.
설계 배경 — 왜 LLM-as-a-Judge인가
RAG R&D 2단계에서 구축한 RAGAS 평가 프레임워크의 핵심 로직(5차원 가중 평가 + Silver Dataset 기반 GT 생성)을 AI Console Eval 플랫폼으로 이식했습니다.
R&D에서 검증된 평가 체계를 그대로 제품화하여, 배포된 파이프라인의 품질을 비개발자도 즉시 평가할 수 있도록 했습니다.
또한 Judge 모델과 응답 생성 모델의 분리가 핵심 설계 원칙입니다.
동일 모델이 생성과 평가를 모두 수행하면 자기 편향(self-bias)이 발생하여 환각이 포함된 긴 답변에 높은 점수를 부여하는 문제를 실제 실험에서 확인했습니다.
| 구성 | 응답 생성 (RAG LLM) | 평가 (Judge) | 결과 |
|---|---|---|---|
| Before (자기평가) | Qwen3-30B (vLLM) | Qwen3-30B (vLLM) | naive-rag 올만점 — 환각 미감지 |
| After (분리평가) | Qwen3-30B (vLLM) | GPT-4o (OpenAI API) | fusion-rag 우세 — 환각 정확히 감지 |
LLM-as-a-Judge 5차원 가중 평가
G-Eval 스타일의 상세 루브릭과 Chain-of-Thought 추론을 적용하여, 각 차원별 1-5점 Likert 척도로 평가 후 0-1 정규화합니다.
| 차원 | 가중치 | 평가 내용 |
|---|---|---|
| Faithfulness | 30% | 응답이 검색된 문맥에 충실한가 (환각 여부) |
| Relevance | 25% | 응답이 질문에 적절히 대응하는가 |
| Completeness | 20% | 질문에 필요한 정보를 빠짐없이 포함하는가 |
| Coherence | 15% | 응답이 논리적으로 일관되는가 |
| Fluency | 10% | 자연스럽고 읽기 쉬운 문장인가 |
실제 A/B 테스트 결과 — VLM 파싱 vs 기본 파싱
동일 문서(2025년 공공AX 프로젝트 공모안내서, 69페이지)를 두 파이프라인에 각각 업로드하여 동일 질문으로 GPT-4o Judge 평가를 수행했습니다.
| 파이프라인 | 파서 | 검색 전략 | Reranker |
|---|---|---|---|
| Pipeline A: naive-rag | pymupdf4llm (기본) | Dense only, top_k=5 | 없음 |
| Pipeline B: fusion-rag | WigtnOCR VLM (4병렬) | Hybrid + Filtered, top_k=10 | Qwen3 Reranker 8B |
GPT-4o Judge 평가 결과:
| 평가 차원 | naive-rag (A) | fusion-rag (B) | 차이 | 승자 |
|---|---|---|---|---|
| Relevance (25%) | 1.00 | 1.00 | 0 | tie |
| Faithfulness (30%) | 0.75 | 1.00 | +0.25 | B |
| Coherence (15%) | 1.00 | 1.00 | 0 | tie |
| Fluency (10%) | 1.00 | 1.00 | 0 | tie |
| Completeness (20%) | 0.75 | 1.00 | +0.25 | B |
| Weighted Overall | 0.888 | 1.000 | +0.113 | B |
GPT-4o Judge의 감점 근거:
• Faithfulness −0.25 — Context에 없는 "민간부담금 70%", "현물은 인건비로만" 등 외부 지식을 혼입하여 답변 생성 (환각)
• Completeness −0.25 — ⑫검역관리·⑭특허정보·⑮법제정보 분과의 "연구소 참여 가능" 차이점을 놓침. 모든 분과가 동일하다고 잘못 기술
→ VLM 파싱(WigtnOCR)으로 구조화된 Markdown이 더 정확한 Context를 제공하여, LLM이 환각 없이 완전한 답변을 생성함을 정량적으로 확인
A/B 테스트 통계 검증
| 검증 방법 | 용도 |
|---|---|
| Mann-Whitney U test | 비모수 통계 검정 (정규성 가정 불필요) |
| Bootstrap CI (1000회 리샘플링) | 95% 신뢰구간 추정 |
| Cohen's d | 효과 크기 해석 (small/medium/large) |
| Holm-Bonferroni 보정 | 다중 비교 시 Type I 오류 방지 |
| Redis 캐싱 | Baseline 결과 캐싱으로 A/B 테스트 비용/시간 절반 |
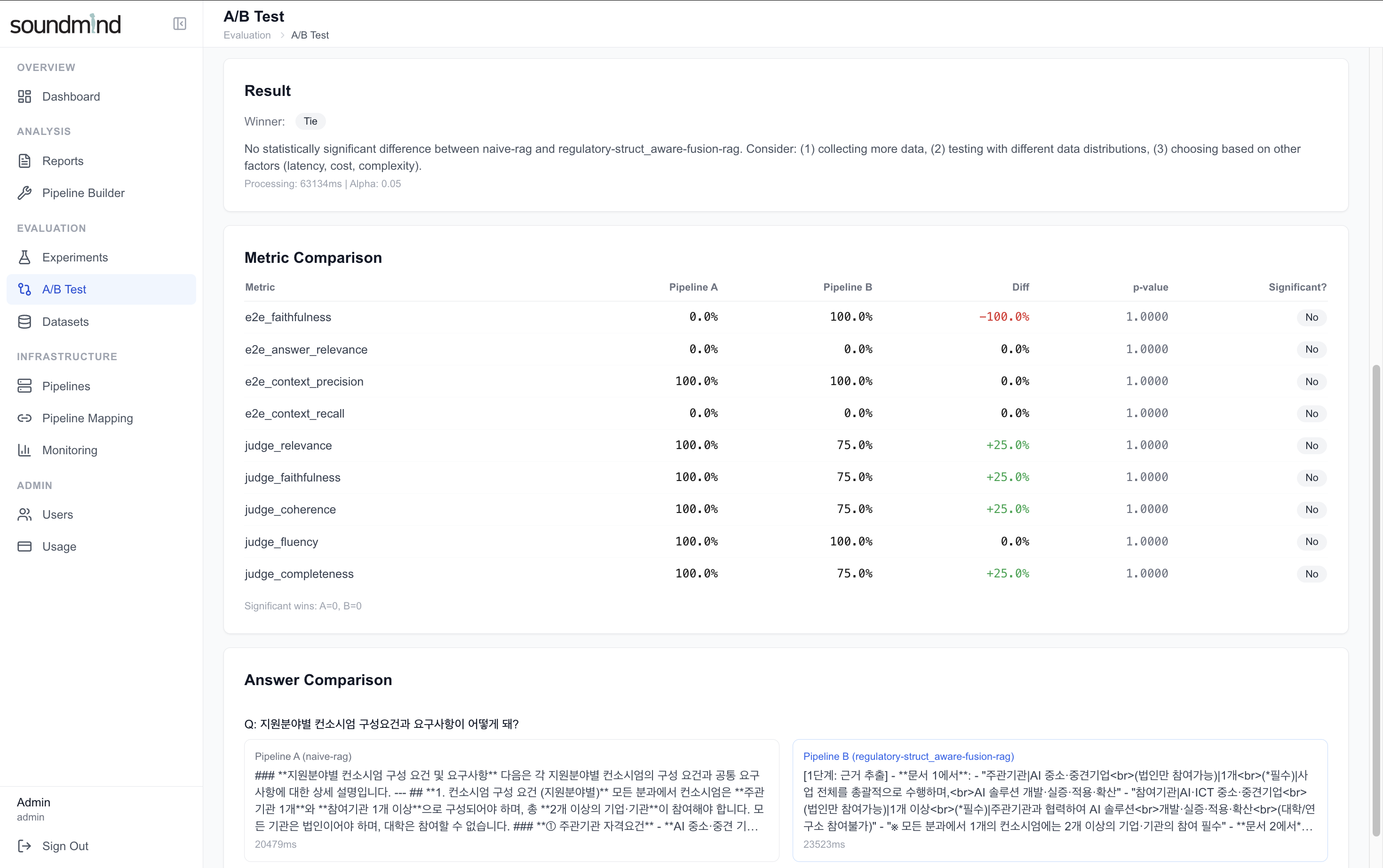 1. Before — Qwen3-30B 자기평가: RAGAS E2E 메트릭 + Judge 올만점 (환각 미감지)
1. Before — Qwen3-30B 자기평가: RAGAS E2E 메트릭 + Judge 올만점 (환각 미감지)
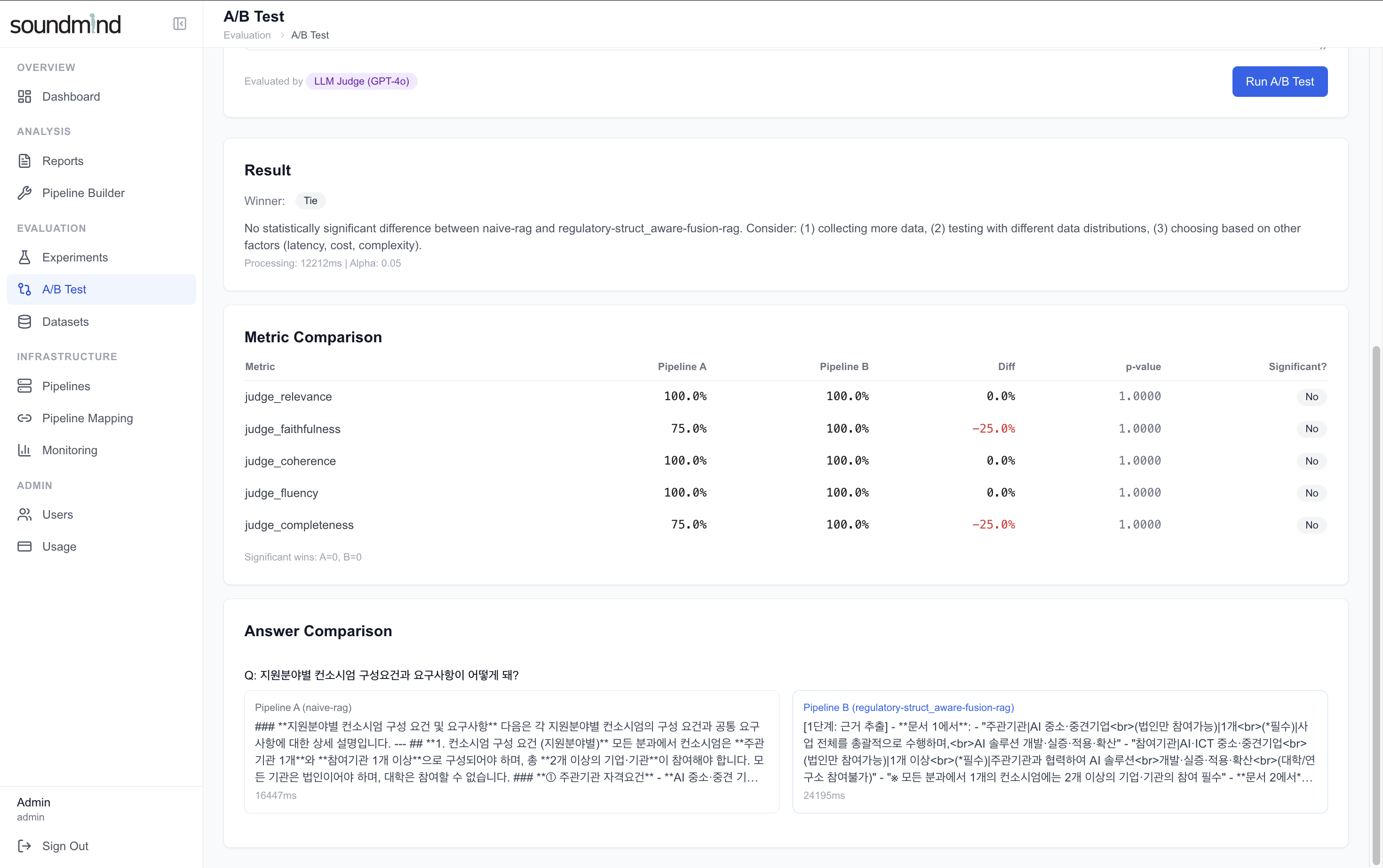 2. After — GPT-4o 분리평가: Faithfulness·Completeness에서 fusion-rag 우세 (환각 정확 감지)
2. After — GPT-4o 분리평가: Faithfulness·Completeness에서 fusion-rag 우세 (환각 정확 감지)
AI Console — Monitoring (실시간 모니터링)
전체 에코시스템의 로그를 중앙에서 수집·시각화하여 장애를 조기에 감지하고, 서비스 상태를 실시간으로 파악합니다.
설계 배경 — 왜 Grafana + Loki인가
GPU 서버(RTX PRO 6000 ×2)에서 LLM 서빙과 RAG Pipeline이 동시에 운용되는 환경에서, ELK 스택의 리소스 소비는 부담이었습니다.
Grafana + Loki + Promtail 조합은 Docker 소켓 기반 비침투적(non-intrusive) 자동 수집으로 앱 코드 수정 없이 전체 에코시스템을 모니터링하며, ELK 대비 현저히 낮은 리소스를 사용합니다.
인프라 구성
- Grafana 11.5.2 + Loki 3.4.2 + Promtail 3.4.2 기반 중앙 로그 수집
- Docker 소켓 기반 자동 수집 — 새 컨테이너 추가 시 설정 변경 불필요
- Labels(인덱스용, 카디널리티 낮음: level, platform, service)와 Structured Metadata(카디널리티 높음: logger, module, function)를 분리하여 Loki 인덱싱 효율 최적화
대시보드
- 4개 전용 대시보드: System Overview · AI Platform · Analysis · Eval
- Model Serving 로그 대시보드 별도 운용
- 서비스 상태, GPU 할당, Pipeline 관리, 사용자/권한 설정까지 운영 전반 커버
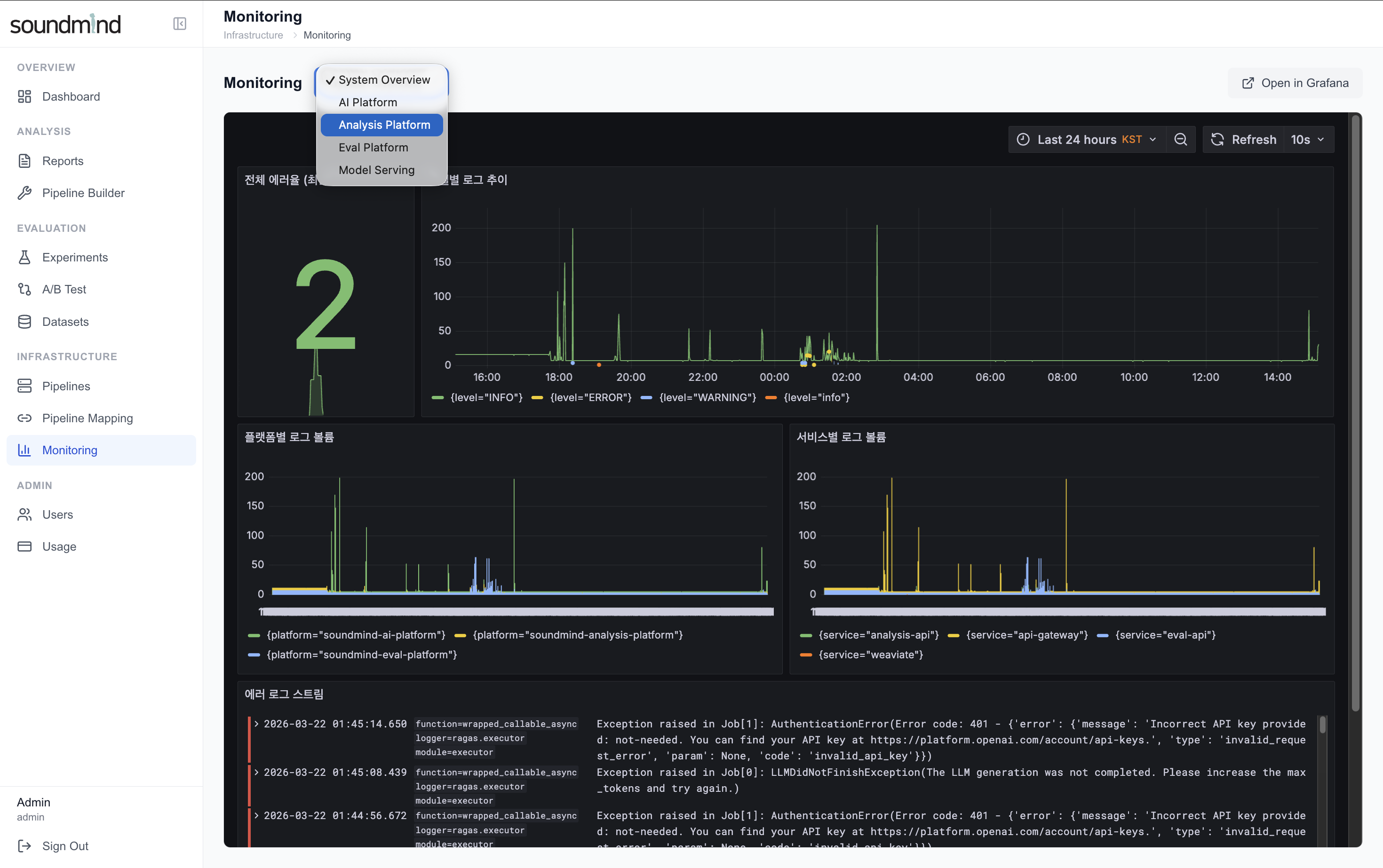 1. System Overview — 전체 에코시스템 실시간 로그 대시보드
1. System Overview — 전체 에코시스템 실시간 로그 대시보드
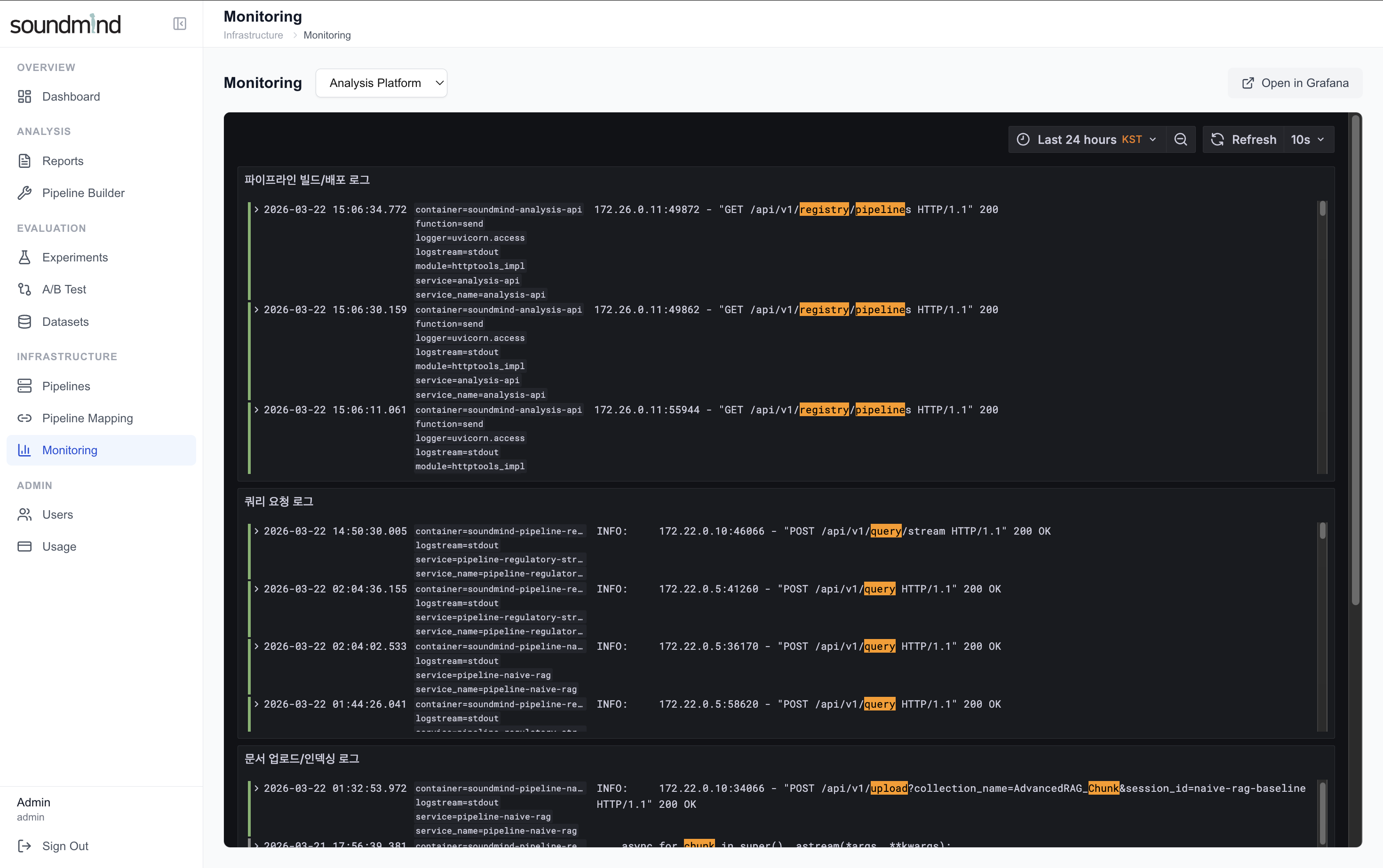 2. Platform Detail — 플랫폼별 상세 메트릭 및 에러 추적
2. Platform Detail — 플랫폼별 상세 메트릭 및 에러 추적
AI Platform — 고객 대면 Playground (B2B SaaS)
AI Console에서 생성·배포된 맞춤형 RAG Pipeline을, 고객이 현장에서 즉시 PoC 체험할 수 있는 Playground 서비스 플랫폼입니다. 영업팀이 클라우드 서버에 접속하여 고객 문서를 업로드하고 바로 시연할 수 있도록 설계되었으며, 3개의 독립 Agent 세션을 제공합니다. React 19 Web Console + FastAPI API Gateway(JWT 멀티테넌트 인증, SSE 스트리밍)로 구현되었습니다.
Web Console
 1. Login — JWT 기반 멀티테넌트 인증
1. Login — JWT 기반 멀티테넌트 인증
 2. Portal — RAG Agent · Chat Agent · AICC Agent 서비스 선택
2. Portal — RAG Agent · Chat Agent · AICC Agent 서비스 선택
인증 · 권한 — 5단계 진화
MVP 무인증에서 출발하여 PoC 납품 단계까지 점진적으로 확장했습니다. Company(slug) + Team + Session 3계층 멀티테넌트 격리를 적용하여 고객사별 데이터를 분리합니다.
| 단계 | 인증 방식 | 핵심 변화 |
|---|---|---|
| ① | 무인증 | MVP 빠른 검증 |
| ② | JWT | DB 연동 사용자 인증 |
| ③ | Guest Tier | 회원가입 없이 체험 (refresh token 비활성화) |
| ④ | 3-tier RBAC | Admin · Manager · User · Guest 역할별 접근 제어 |
| ⑤ | Guest BYOK | 게스트가 자체 API 키로 클라우드 LLM 직접 호출 |
① RAG Agent — 문서 기반 Q&A
고객이 업로드한 문서를 기반으로 질문에 답변하는 문서 특화 Q&A 에이전트입니다. AI Console Analysis에서 고객 문서 특성에 맞게 자동 생성·배포된 RAG Pipeline을 AI Platform이 자동으로 감지하여 연결합니다. 고객마다 서로 다른 맞춤형 파이프라인이 연결되므로, 동일한 플랫폼 위에서 고객별로 최적화된 검색·응답 경험을 제공합니다.
- Dynamic Pipeline Routing — 고객사(Company)별 PipelineMapping 테이블에서 파이프라인 URL을 조회하여 동적으로 라우팅. 최대 99개 파이프라인 동시 운용(9201~9299), httpx.AsyncClient lazy 초기화 + 커넥션 풀링
- Graceful Degradation — 파이프라인 장애 시 Direct LLM 응답으로 자동 전환(fallback: true 메타데이터 포함), 사용자 요청이 끊기지 않는 설계
- Retrieval Insight 3-Panel — (1) Query Transformation: 원본 질의 → 5개 최적화 쿼리, (2) Hybrid Search Score: Dense/Sparse 점수 바 차트, (3) Reranking Impact: 순위 변동 시각화(#1 Gold · #2 Silver · #3 Bronze 뱃지). SSE 이벤트로 실시간 스트리밍
- SSE 실시간 스트리밍 — agent_start → processing → llm_stream(토큰 단위) → final_response → done 이벤트 체인. StreamingThinkParser가 <think> 태그를 실시간 분리하여 추론 과정과 답변을 동시 렌더링
RAG Agent
 1. RAG Agent 메인 — 문서 기반 Q&A Playground
1. RAG Agent 메인 — 문서 기반 Q&A Playground
 2. Chat Session — 문서 기반 Q&A 대화 및 SSE 실시간 스트리밍
2. Chat Session — 문서 기반 Q&A 대화 및 SSE 실시간 스트리밍
 3. 문서 업로드 — 고객 문서 업로드 및 파이프라인 연결
3. 문서 업로드 — 고객 문서 업로드 및 파이프라인 연결
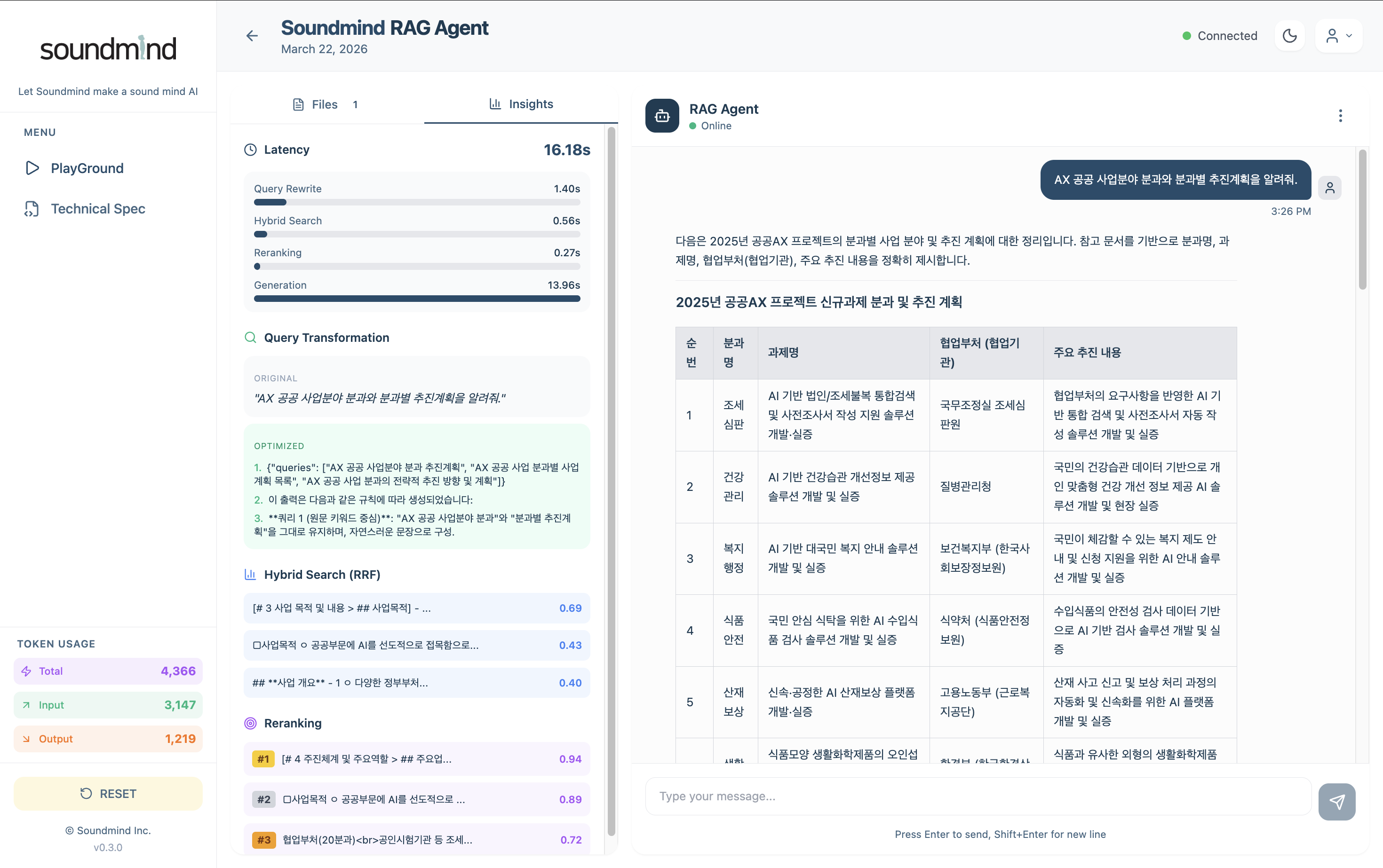 4. Retrieval Insight — Query Transformation + Hybrid Score + Reranking Impact 시각화
4. Retrieval Insight — Query Transformation + Hybrid Score + Reranking Impact 시각화
② Chat Agent — 자율형 AI 에이전트 (MVP 구현 완료)
문서에 국한되지 않고, LLM이 스스로 상황을 판단하여 필요한 도구를 선택·호출하는 자율형 에이전트입니다. LangGraph ReAct 아키텍처 기반으로 복합 태스크를 단계적으로 수행합니다.
- LangGraph StateGraph — agent(LLM 호출) → tools(도구 실행) 2노드 그래프, tool_calls 존재 여부로 조건부 라우팅, MemorySaver로 세션 상태 유지, 무한 루프 방지 10회 이터레이션 제한
- 내장 도구 3종 — Tavily Search(웹 검색, 최대 5결과), File Read(TXT/PDF, 보안 체크: .env/.ssh/.aws 차단), Report Agent(요약/분석/회의록/커스텀 4종 문서 생성 서브에이전트)
- MCP 확장 — Model Context Protocol 클라이언트로 외부 도구 동적 추가 가능
- 멀티 프로바이더 — OpenAI / vLLM / Gemini 동일 인터페이스 지원, Guest BYOK(Bring Your Own Key)로 게스트 사용자 자체 API 키 사용
Chat Agent
 1. Chat Agent Toolkit — 모델·도구·MCP·Sub-agent 선택 후 Build
1. Chat Agent Toolkit — 모델·도구·MCP·Sub-agent 선택 후 Build
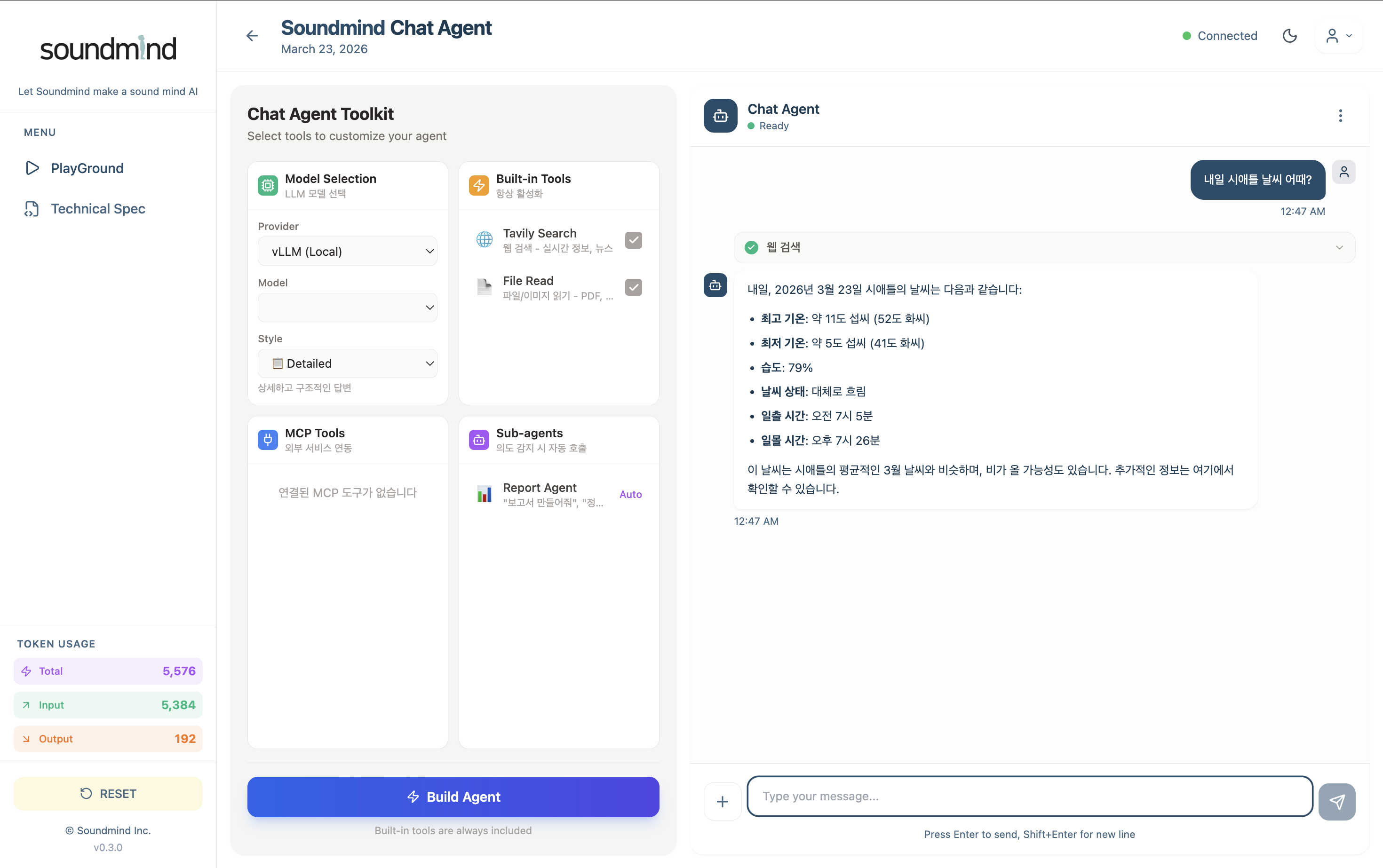 2. Chat Session — Tavily Search 도구 호출 및 응답
2. Chat Session — Tavily Search 도구 호출 및 응답
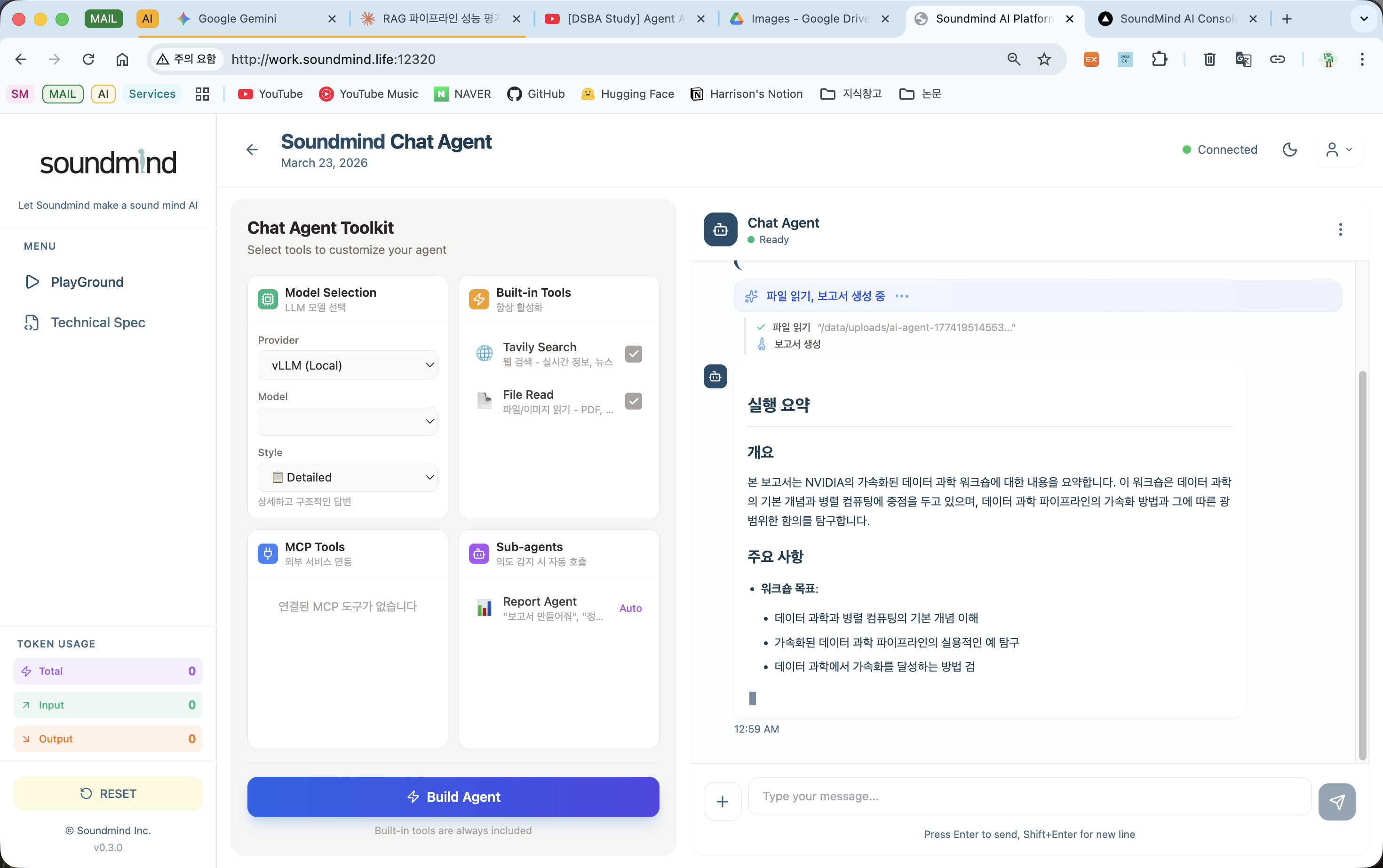 3. File Read — 파일 읽기 + Report Agent 자동 호출로 보고서 생성
3. File Read — 파일 읽기 + Report Agent 자동 호출로 보고서 생성
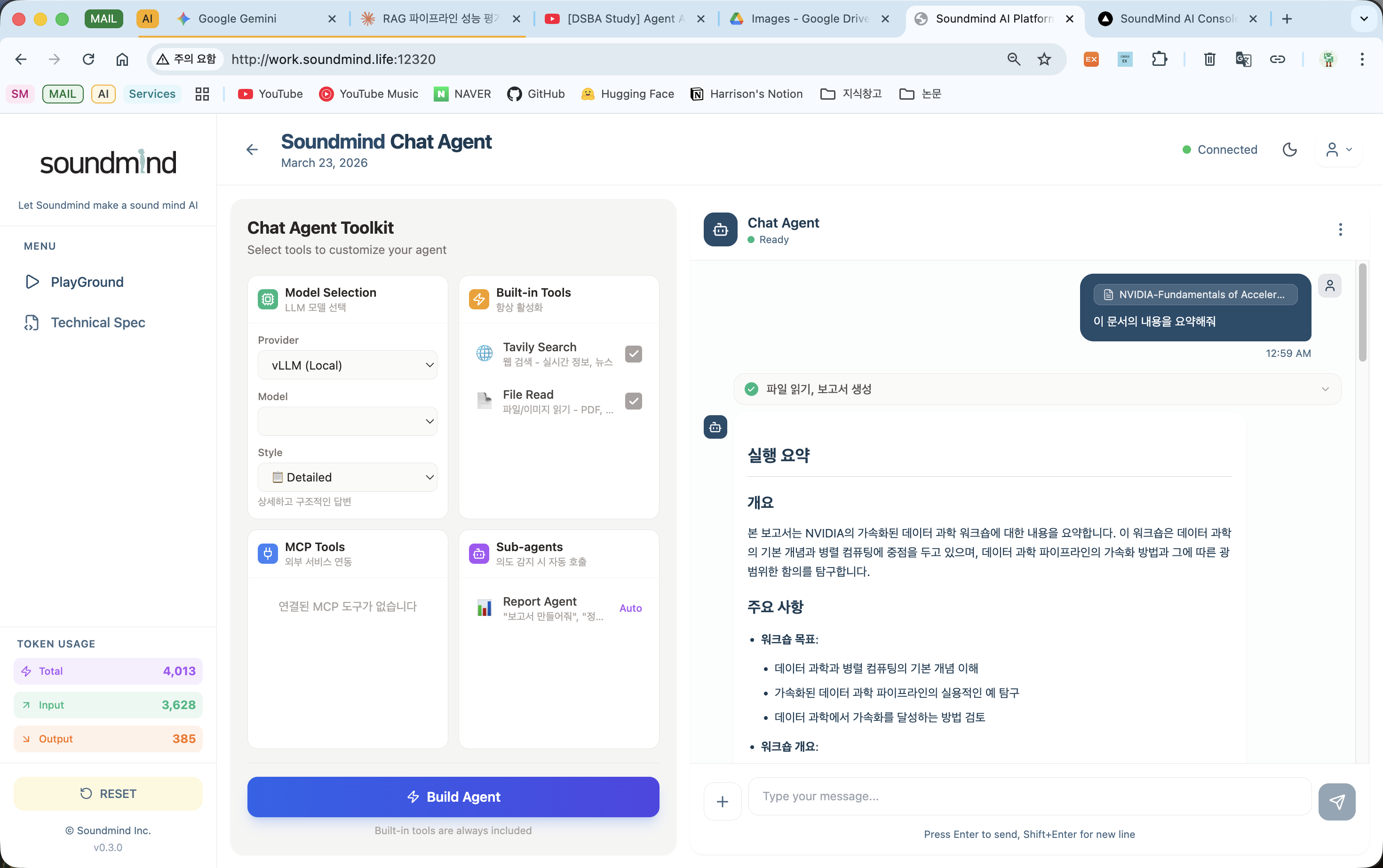 4. Report 완료 — 문서 요약 보고서 생성 결과
4. Report 완료 — 문서 요약 보고서 생성 결과
③ AICC Agent — AI 컨택센터 (퇴사 시점 미착수)
RAG Agent의 문서 기반 응답 능력과 Chat Agent의 자율 도구 사용 능력을 결합하여, 고객 상담 시나리오에 특화된 AI 컨택센터 에이전트로 기획되어 있었으나, 본인 퇴사(2026.03) 전까지 본격 개발에는 착수하지 못했습니다.
Next Step (퇴사 시점 로드맵)
본인 퇴사(2026.03) 시점 기준의 향후 계획입니다. 이후 진행 상황은 사운드마인드 내부에서 별도 진행되었습니다.
WigtnOCR 연동 — VLM 기반 문서 파싱 고도화
텍스트 추출 중심의 파싱을 VLM(Vision-Language Model) 기반으로 확장하여, 표·차트·레이아웃 등 시각적 구조까지 보존하는 방향으로 확장하는 것이 목표였습니다. 별도 연구 프로젝트로 진행한 WigtnOCR(Qwen3-VL-2B LoRA fine-tuning → 비교 실험 4개 모델 중 Table TEDS 1위, 15배 큰 30B 모델 성능 초과)의 성과를 Ecosystem에 직접 적용하여, A/B 테스트에서 확인된 VLM 파싱의 품질 우위(0.888 → 1.000)를 전체 파이프라인에 확대하려는 계획이 있었습니다.
정식 배포 (계획)
- Beta 테스트 피드백 기반 UX 개선 및 안정성 확보
- 평가 → 분석 → 재배포 Feedback Loop으로 자동 최적화 사이클 구축
- AICC Agent(AI 컨택센터) 개발 및 3개 Agent 서비스 완성