문서 파싱의 구조 보존이 RAG 파이프라인에 미치는 영향 연구
Abstract
AI 파이프라인의 첫 단계인 Document Parsing에서 구조 정보가 손실되면, 이후 어떤 청킹 전략이나 검색 알고리즘을 적용해도 품질의 한계에 부딪힙니다. 이 실험에서는 이 가설을 정량적으로 검증하기 위해, 표 안의 표, 이미지 기반 테이블, 다단 레이아웃 등 복잡한 구조를 포함하는 문서를 대상으로 기존 텍스트 추출/OCR 방식(PyMuPDF, RapidOCR)과 VLM(Qwen3-VL) 기반 구조화 파싱을 Lexical Accuracy, Structural Integrity, Downstream Chunking Quality, Retrieval Impact 네 가지 차원에서 비교 분석했습니다.
기존 OCR 파서(PyMuPDF, RapidOCR)는 텍스트 추출 자체는 잘 수행합니다(CER 40–51%). 그러나 추출된 결과에 구조 정보가 전혀 없어 Structure F1은 0%입니다. 여기에 VLM 기반 2-Stage Parsing을 적용하면, 텍스트 추출 품질은 유지하면서 Structure Precision 72.41%, Recall 87.50% (F1 79.25%)을 달성합니다. 다만 CER이 소폭 증가하는 트레이드오프가 존재하며, 이는 Prompt Engineering(v1 → v2)을 통해 개선했습니다. 자세한 실험 과정과 결과는 아래에서 살펴보겠습니다.
1. Motivation
1.1 문제 인식
고객사의 RAG 파이프라인을 구축하면서 반복적으로 마주한 문제가 있습니다. 고객사 문서에는 표 안의 표, 이미지 기반 테이블, 다단 레이아웃 등 복잡한 구조가 포함되어 있었습니다. 이런 문서를 기존 OCR 파이프라인으로 추출하면 테이블이 중간에 잘리거나, 다단 레이아웃의 읽기 순서가 뒤섞이는 현상이 발생했습니다. 청킹 전략을 바꾸고, 임베딩 모델을 교체하고, Reranker를 추가해도 근본적인 한계가 해소되지 않았습니다.
결국 문제의 원인은 파이프라인의 첫 단계인 Data Parsing에 있었습니다. 구조가 손실된 상태로 넘어온 텍스트는, 이후 어떤 고도화를 적용해도 복원이 불가능합니다.
예를 들어, 아래와 같은 2단 학술 논문을 PyMuPDF로 추출하면 어떻게 될까요?
# 기대하는 결과
1. Introduction
문단 1 내용...
문단 2 내용...
# 실제 결과 (PyMuPDF)
1. Introduction 문단 1 첫 줄 문단 2 첫 줄
문단 1 두번째 줄 문단 2 두번째 줄...이러한 구조적 손실은 청킹 품질 저하 → 검색 정확도 하락으로 직결됩니다. 그렇다면 파싱 단계에서 구조를 보존하면 이 문제를 해결할 수 있을까요? VLM 기반 구조화 파싱을 통해 정량적으로 검증해 보겠습니다.
1.2 Research Questions
이 실험에서는 네 가지 핵심 질문에 답하고자 합니다:
| RQ | 역할 | 질문 | 측정 지표 |
|---|---|---|---|
| RQ1 | 전제조건 | VLM 기반 파싱이 텍스트 정확도를 유지하는가? | CER, WER |
| RQ2 | 핵심 가설 | VLM 기반 파싱이 문서 구조를 더 잘 보존하는가? | Structure F1 |
| RQ3 | 효과 검증 | 구조 보존이 다운스트림(청킹) 품질을 향상시키는가? | BC Score, CS |
| RQ4 | End-to-End | 개선된 청킹이 실제 검색 정밀도를 높이는가? | Hit Rate@k, MRR |
1.3 "구조화된 데이터" 정의
이 실험에서 "구조화된 데이터"란 다음을 의미합니다:
- 마크다운 헤딩: 문서의 계층적 섹션 구조 (#, ##, ###)
- 테이블: 행/열로 구성된 표 형식 데이터 (| col1 | col2 |)
- 리스트: 순서 있는/없는 목록 (1., -, *)
- 읽기 순서: 다단 레이아웃에서 올바른 텍스트 흐름
1.4 Core Hypothesis
"파이프라인의 첫 단계(Data Parsing)에서 구조를 보존하면, 동일한 downstream 처리(청킹, 임베딩, 검색)로도 더 높은 품질을 달성할 수 있다."
2. Related Work
2.1 Traditional Text Extraction & OCR Approaches
전통적인 텍스트 추출/OCR 파이프라인(Tesseract, RapidOCR, PyMuPDF)은 문자 인식에는 우수하지만 레이아웃 이해 능력이 제한적입니다. 특히 다단 레이아웃, 표, 중첩 구조에서 읽기 순서가 뒤섞이는 문제가 발생합니다.
2.2 Layout-Aware Models
LayoutLM 시리즈(v1, v2, v3)는 텍스트와 레이아웃 정보를 함께 학습하여 문서 이해 성능을 향상시켰습니다. 하지만 이러한 모델들에는 한계가 있습니다:
- 사전 학습된 레이아웃 패턴에 의존
- 새로운 문서 형식에 대한 일반화 제한
- 구조화된 출력(마크다운) 생성에 최적화되지 않음
2.3 Vision-Language Models
Qwen-VL, GPT-4V, Claude 3 등 최신 VLM은 이미지를 직접 이해하고 구조화된 텍스트를 생성할 수 있습니다. 이 실험에서는 Qwen3-VL-2B-Instruct를 사용했습니다:
- End-to-End 구조화: 이미지 → 마크다운 직접 변환
- Zero-shot 일반화: 학습하지 않은 문서 형식도 처리 가능
- 다국어 지원: 한국어, 영어 등 다양한 언어 처리
2.4 Prompt Engineering Evolution
VLM 기반 문서 파싱에서 프롬프트 설계는 결과 품질에 큰 영향을 미칩니다. 이 실험에서는 "Extraction" 패러다임에서 "Transcription" 패러다임으로 전환하여 Hallucination을 최소화하는 전략을 도입했습니다.
2.5 Semantic Chunking & Evaluation
RAG 파이프라인에서 청킹 품질 평가는 아직 표준화되지 않았습니다. 이 실험에서는 다음 메트릭을 활용합니다:
| 메트릭 | 설명 | 출처 |
|---|---|---|
| Structure F1 | 구조 요소 검출 정확도 | 본 연구 정의 |
| Boundary Clarity (BC) | 인접 청크 간 의미적 분리도 | Zhao et al. (2025), MoC |
| Chunk Stickiness (CS) | 청크 내 문장 결속도 (Structural Entropy) | Zhao et al. (2025), MoC |
3. Methodology
3.1 평가 프레임워크
4단계 평가 프레임워크를 설계하여 문서 파싱 품질을 다각도로 측정했습니다:
┌──────────────────────────────────────────────────────────────────────────────────┐
│ EVALUATION FRAMEWORK │
├──────────────────────────────────────────────────────────────────────────────────┤
│ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ RQ1 │ │ RQ2 │ │ RQ3 │ │ RQ4 │ │
│ │ Lexical │ → │Structural│ → │Downstream│ → │Retrieval │ │
│ │ Accuracy │ │Integrity │ │ Chunking │ │ Impact │ │
│ └──────────┘ └──────────┘ └──────────┘ └──────────┘ │
│ │ │ │ │ │
│ ▼ ▼ ▼ ▼ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ CER, WER │ │ F1 │ │ BC, CS │ │Hit Rate, │ │
│ │ │ │ │ │ │ │ MRR │ │
│ └──────────┘ └──────────┘ └──────────┘ └──────────┘ │
│ │
└──────────────────────────────────────────────────────────────────────────────────┘3.2 파서 아키텍처
4가지 파서 조합을 비교 평가했습니다:
| Parser | Stage 1 | Stage 2 | 적합 문서 유형 |
|---|---|---|---|
| Text-Baseline | PyMuPDF | - | 디지털 PDF (텍스트 레이어 존재) |
| Image-Baseline | RapidOCR | - | 스캔 PDF, 이미지 기반 문서 |
| Text-Advanced | PyMuPDF | VLM 구조화 | 디지털 PDF + 구조 추출 |
| Image-Advanced | RapidOCR | VLM 구조화 | 스캔 PDF + 구조 추출 |
3.3 PDF Type 분류
같은 "PDF"라도 내부 구조에 따라 파서 동작이 크게 달라집니다. 이 실험에서는 PDF를 다음 4가지 Type으로 분류하여 테스트 커버리지를 관리합니다.
| PDF Type | 특성 | 파서 동작 차이 |
|---|---|---|
| Digital PDF | 텍스트 레이어 존재 (arXiv, Word→PDF) | PyMuPDF가 텍스트 직접 추출, OCR 불필요 |
| Scanned PDF | 이미지만 존재 (스캔 문서) | OCR 필수, 스캔 품질에 따라 정확도 편차 큼 |
| Hybrid PDF | 일부 페이지만 스캔 | 페이지별 처리 전략 필요 |
| Image-heavy PDF | 텍스트는 있으나 표/차트가 이미지로 삽입 | 텍스트는 추출되나 표 구조 손실 |
분류 기준으로 80%를 사용하는 것은 휴리스틱입니다. 100%를 사용하면 단 1페이지라도 다른 유형이면 분류가 실패하므로, 약간의 여유를 두어 주요 특성을 반영합니다.
import fitz # PyMuPDF
def classify_pdf(pdf_path):
"""PDF를 4가지 Type으로 분류한다."""
doc = fitz.open(pdf_path)
text_pages = 0
image_pages = 0
image_heavy_pages = 0
for page in doc:
text = page.get_text().strip()
images = page.get_images()
# 텍스트가 있고 이미지가 많으면 Image-heavy
if len(text) > 100 and len(images) > 3:
image_heavy_pages += 1
elif len(text) > 100:
text_pages += 1
elif images:
image_pages += 1
total = len(doc)
if image_heavy_pages > total * 0.5:
return "Image-heavy PDF"
elif text_pages > total * 0.8:
return "Digital PDF"
elif image_pages > total * 0.8:
return "Scanned PDF"
else:
return "Hybrid PDF"3.4 VLM 프롬프트 전략
본 연구에서 가장 결정적인 성능 차이를 만든 요인은 모델이나 파이프라인 구조가 아닌 프롬프트 설계였습니다. 동일한 Qwen3-VL-2B 모델에서 프롬프트만 변경하여 Structure F1이 0%에서 77~79%로 개선되었습니다. 이 절에서는 v1에서 v2로의 진화 과정과 그 근거를 상세히 기술합니다.
3.4.1 Prompt v1: Extraction Expert (Baseline)
초기 프롬프트는 VLM을 "전문가(expert)"로 프레이밍하여 문서의 모든 정보를 추출하도록 지시했습니다.
# Prompt v1 — Extraction Expert
PROMPT_V1 = """
You are an expert document extraction assistant. Your task is to extract
all information from the given document image and present it in a clear,
organized markdown format.
Please extract:
1. All text content
2. Tables (preserve structure)
3. Lists and enumerations
4. Headers and section titles
Format the output as clean markdown.
"""이 프롬프트로 두 Advanced 파서 모두 Structure F1 = 0%를 기록하며 완전히 실패했습니다. "expert"라는 역할 부여와 "extract... present... organized"라는 지시가 모델에게 해석과 재구성을 유도했고, 2B 파라미터의 소형 모델은 이를 hallucination으로 수행하여 원본에 없는 구조를 만들어내거나 기존 구조를 무시했습니다.
3.4.2 Prompt v2: Transcription Engine (Selected)
v1의 실패를 분석한 뒤, 근본적으로 다른 접근을 설계했습니다. 핵심 전환은 "추출(Extraction)"에서 "전사(Transcription)"로의 패러다임 변경입니다.
# Prompt v2 — Transcription Engine (Selected)
PROMPT_V2 = """
You are a document transcription engine. Your sole purpose is to convert
the given image into markdown text format. You MUST only transcribe what
is actually visible in the image - do not add any additional information,
explanations, or content that is not present in the original document.
Rules:
1. Transcribe ALL visible text exactly as shown
2. Use markdown formatting to preserve structure (headers, lists, tables)
3. For tables, use markdown table syntax with proper alignment
4. Preserve the original language (Korean, English, etc.)
5. Do NOT add explanations, summaries, or interpretations
6. Do NOT add information that is not visible in the image
7. If text is unclear, indicate with [unclear] rather than guessing
8. Maintain original paragraph breaks and spacing intent
"""VLM이 출력한 텍스트를 마크다운 구조로 변환하는 2단계(Text Structuring)에서는 번호-마크다운 레벨 간의 명시적 매핑 규칙을 별도로 정의했습니다.
# Text Structuring Prompt — 명시적 구조 매핑 규칙
SYSTEM_PROMPT = """You are a Markdown formatting expert. Your task is to
convert plain text into well-structured Markdown format.
CRITICAL RULES - You MUST follow these:
1. ALWAYS use # symbols for headings. This is mandatory.
2. Document title → # Title
3. Section numbers like "1 Introduction" or "1. Introduction" → ## 1. Introduction
4. Subsections like "3.1 Method" → ### 3.1 Method
5. Sub-subsections like "3.1.1 Details" → #### 3.1.1 Details
6. Tables with aligned columns → Markdown table with | separators
7. Bullet points → - item
8. Numbered lists → 1. item
NEVER output plain text headings without # symbols."""3.4.3 v1 vs v2 설계 차이 분석
두 프롬프트의 핵심 차이를 5개 차원에서 비교합니다. 각 차원이 2B 소형 모델의 행동에 어떤 영향을 미쳤는지 분석합니다.
| 설계 차원 | v1 (Extraction Expert) | v2 (Transcription Engine) | 영향 |
|---|---|---|---|
| Role Framing | "expert extraction assistant" | "transcription engine" | "assistant"는 해석을 유도, "engine"은 기계적 전사를 유도 |
| Task Definition | "Extract all information and present it" | "You MUST only transcribe what is actually visible" | "present"는 재구성 허용, "MUST only"는 범위를 제한 |
| Explicit Negation | (없음) | "Do NOT add explanations, summaries, or interpretations" | 소형 모델은 암묵적 기대를 추론하지 못하므로 명시적 금지가 필수 |
| Uncertainty Handling | (없음 — 모델이 추측) | "If text is unclear, indicate with [unclear] rather than guessing" |
hallucination의 주요 원인인 "추측"을 차단하는 안전장치 |
| Structure Mapping | "Headers and section titles" (암묵적) | "1 Introduction" → ## 1. Introduction"3.1 Method" → ### 3.1 Method (명시적) |
2B 모델의 제한된 추론 능력을 규칙 기반 매핑으로 보완 |
3.4.4 결과: Structure F1 변화
| Prompt Version | Text-Advanced | Image-Advanced |
|---|---|---|
| v1 (Extraction Expert) | 0% | 0% |
| v2 (Transcription Engine) | 79.25% | 77.78% |
| Delta | +79.25pp | +77.78pp |
3.4.5 Prompt Engineering Lessons
본 실험에서 도출한 소형 VLM(2B) 대상 프롬프트 설계 원칙을 정리합니다. 이 원칙들은 대형 모델에서는 불필요할 수 있으나, 자원 제약 환경에서 소형 모델을 활용할 때 실질적인 가이드라인이 됩니다.
- Explicit Negation: "Do NOT add"는 암묵적 기대보다 효과적입니다. 소형 모델은 "clean markdown"이라는 지시에서 "불필요한 내용을 추가하지 말 것"을 추론하지 못합니다.
- Role Framing: "transcription engine"은 "expert assistant"보다 기계적·리터럴한 행동을 유도합니다. "expert"는 모델에게 판단과 해석의 여지를 부여하여 hallucination 위험을 높입니다.
-
Uncertainty Handling:
[unclear]마커를 제공하면 모델이 불확실한 입력에 대해 "추측" 대신 "표시"를 선택할 수 있는 경로가 생깁니다. - Deterministic Mapping: "섹션 번호 → 마크다운 헤딩 레벨"과 같은 규칙 기반 매핑은 소형 모델의 제한된 추론 능력을 보완하는 가장 효과적인 방법입니다.
-
MUST/NEVER Keywords:
강제 키워드(
MUST,NEVER,ALWAYS)는 소형 모델의 instruction following 성능을 향상시킵니다. v2 프롬프트에서 이 키워드들이 없으면 Structure F1이 현저히 낮아지는 것을 확인했습니다.
핵심 교훈: 2B 파라미터 소형 모델에서는 프롬프트가 모델 선택만큼 중요한 변수입니다. 동일한 모델에서 프롬프트 하나의 차이로 Structure F1이 0%에서 79%로 변했다는 사실은, 소형 모델 활용 시 프롬프트 엔지니어링이 모델 스케일업의 대안이 될 수 있음을 시사합니다.
3.5 측정 지표 정의
Character Error Rate (CER)
문자 수준의 정확도를 Levenshtein 편집 거리로 측정합니다:
CER = (Substitutions + Deletions + Insertions) / Reference Length
Word Error Rate (WER)
단어 수준의 정확도를 측정합니다:
WER = (Word Substitutions + Word Deletions + Word Insertions) / Reference Word Count
Structure F1
마크다운 구조 요소(Heading, List, Table) 검출 정확도입니다:
평가 대상 구조 요소:
| Element Type | Pattern | Example |
|----------------|-------------------|----------------------|
| Heading | ^#{1,6}\s+ | # Title, ## Section |
| Unordered List | ^[\s]*[-*+]\s+ | - item |
| Ordered List | ^[\s]*\d+\.\s+ | 1. first |
| Table Row | ^\|.+\|$ | | col1 | col2 | |Boundary Clarity (BC)
MoC 논문[1]에 따르면, BC는 인접 청크 간 의미적 분리도를 측정합니다:
BC = 1 - cosine_similarity(chunki, chunki+1)
임베딩 공간에서 연속된 청크가 얼마나 다른지 측정합니다. BC Score가 높을수록 청킹 경계가 의미 단위를 잘 분리함을 의미합니다. 값 범위는 0~1이며, 1에 가까울수록 경계가 명확합니다.
Chunk Stickiness (CS)
MoC 논문[1]에 따르면, CS는 청크 내 문장들의 결속도를 Structural Entropy로 측정합니다:
$$ CS = -\sum_{i} \frac{h_i}{2m} \log_2 \frac{h_i}{2m} $$여기서 hi는 문장 i가 다른 청크와 연결된 정도, m은 총 연결 수입니다. CS가 낮을수록 청크 내 문장들이 강하게 결합되어 있음을 의미합니다. 값이 높으면 문장들이 여러 청크에 분산되어 정보가 파편화됨을 나타냅니다.
4. Experimental Setup
4.1 테스트 문서
| ID | 문서 유형 | 언어 | 특성 | PDF Type |
|---|---|---|---|---|
| test_1 | 정부 공문서 | 한국어 | 스캔, 다단 레이아웃 | Scanned PDF |
| test_2 | 영수증 | 영어 | 이미지, 표 구조 | N/A (이미지 파일) |
| test_3 | 학술 논문 | 영어 | 2단 레이아웃, 표, 수식 | Digital PDF |
4.1.1 커버리지 매트릭스
결과를 일반화하려면 다양한 PDF Type에서 검증이 필요합니다. 현재 커버리지 현황은 다음과 같습니다:
| PDF Type | 현재 커버리지 | 비고 |
|---|---|---|
| Digital PDF | ✓ (test_3) | 텍스트 추출 정확도 높음 |
| Scanned PDF | ✓ (test_1) | VLM Hallucination 위험 확인됨 |
| Hybrid PDF | ✗ | 향후 확장 필요 |
| Image-heavy PDF | △ | test_2는 순수 이미지, PDF 형태로 추가 테스트 필요 |
4.2 실험 환경
# Hardware Configuration
hardware:
gpu: "NVIDIA RTX PRO 6000 Blackwell x2"
vram: "96GB each (96GB x2)"
ram: "128GB DDR5"
storage: "NVMe SSD"
# Parser Configuration
vlm_parser:
model: "Qwen3-VL-2B-Instruct"
temperature: 0.1 # 일관된 출력
max_tokens: 8192 # 긴 문서 지원
image_resolution: 300 DPI
# Chunking Configuration (Controlled Variable)
chunking:
strategy: "semantic"
chunker: "LangChain SemanticChunker"
breakpoint_threshold_type: "percentile"
breakpoint_threshold_amount: 95.0
min_chunk_size: null
# Embedding Configuration
embedding:
chunking_model: "BAAI/bge-m3" # SemanticChunker 경계 검출용
metrics_model: "jhgan/ko-sroberta-multitask" # BC/CS 평가용
# Normalization
normalization:
# CER/WER 측정 시 마크다운 구문은 제거 후 비교
remove_markdown: true
lowercase: false
strip_whitespace: true4.3 A/B 실험 설계
통제 변수: 청킹 알고리즘(SemanticChunker), breakpoint threshold, 임베딩 모델, 검색 방식을 동일하게 유지하고, 독립 변수(파서 유형)만 변경하여 파싱 품질의 영향을 분리 측정했습니다.
4.4 실제 파싱 결과 비교
동일한 학술 논문(Attention Is All You Need)의 테이블을 각 파서로 추출한 결과를 살펴보겠습니다:
Baseline (PyMuPDF) 출력
Layer Type Self-Attention (encoder)
Self-Attention (decoder) Encoder-Decoder Attention
Feed-Forward Complexity per Layer O(n2 · d) O(n2 · d)
Sequential Operations O(1) Minimum Path Length O(1)⚠️ 테이블 구조가 완전히 붕괴되어 텍스트 스트림으로 변환됨
Advanced (VLM) 출력
| Layer Type | Complexity per Layer | Sequential Operations | Minimum Path Length |
|------------|---------------------|----------------------|---------------------|
| Self-Attention (encoder) | O(n² · d) | O(1) | O(1) |
| Self-Attention (decoder) | O(n² · d) | O(1) | O(1) |
| Encoder-Decoder Attention | O(n · m · d) | O(1) | O(1) |
| Feed-Forward | O(n · d²) | O(1) | O(1) |✓ 마크다운 테이블로 구조가 보존되어 청킹 시 테이블이 atomic unit으로 유지됨
5. Results
5.1 RQ1: 전제 조건 검증 (CER/WER)
VLM 기반 파싱이 다운스트림에서 유의미하려면, 먼저 텍스트 정확도가 심각하게 훼손되지 않아야 합니다. 이 전제를 검증하기 위해 CER(Character Error Rate)과 WER(Word Error Rate)을 측정했습니다.
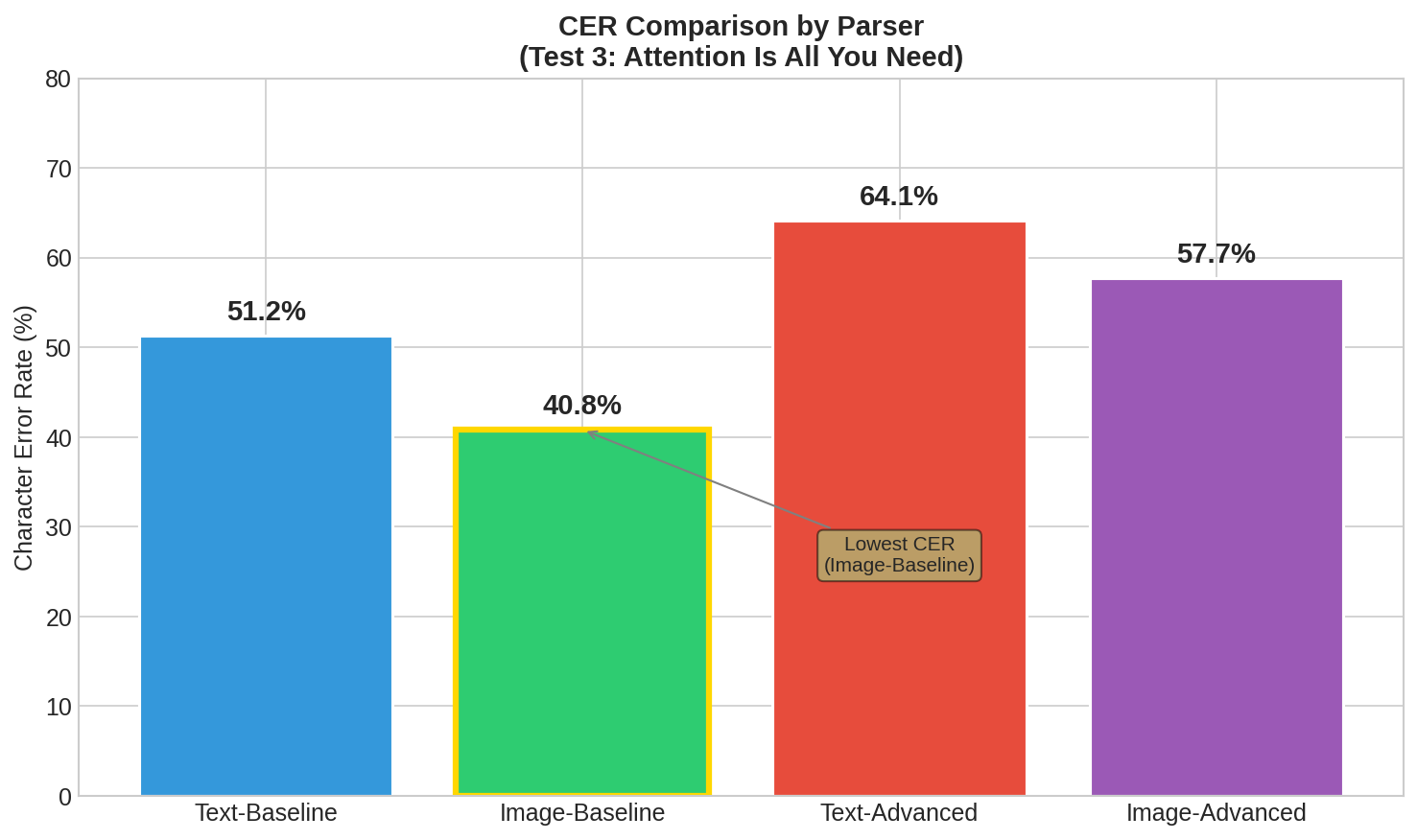
CER (Character Error Rate)
| Document | Text-Baseline | Image-Baseline | Text-Advanced | Image-Advanced |
|---|---|---|---|---|
| test_1 (Korean/Scanned) | N/A | 91.87% | N/A | 536.50% |
| test_2 (영수증 이미지) | 99.59% | 40.80% | 120.54% | 33.09% |
| test_3 (English/Digital) | 51.25% | 40.79% | 64.11% | 57.71% |
WER (Word Error Rate)
| Document | Text-Baseline | Image-Baseline | Text-Advanced | Image-Advanced |
|---|---|---|---|---|
| test_1 (Korean/Scanned) | N/A | 98.21% | N/A | 421.43% |
| test_2 (영수증 이미지) | 100.00% | 52.17% | 115.22% | 43.48% |
| test_3 (English/Digital) | 62.89% | 51.55% | 75.26% | 68.04% |
전제 조건 판정
| 문서 유형 | 판정 | 근거 |
|---|---|---|
| 영어 디지털 PDF | Pass | CER 57.71%, 구조 보존 가치 > 정확도 손실 |
| 영어 스캔 PDF | Pass | CER 33.09%로 오히려 개선 |
| 한글 스캔 PDF | Fail | CER 536% — Hallucination으로 인해 사용 불가 |
5.2 RQ2: 구조 보존 효과 (Structure F1)
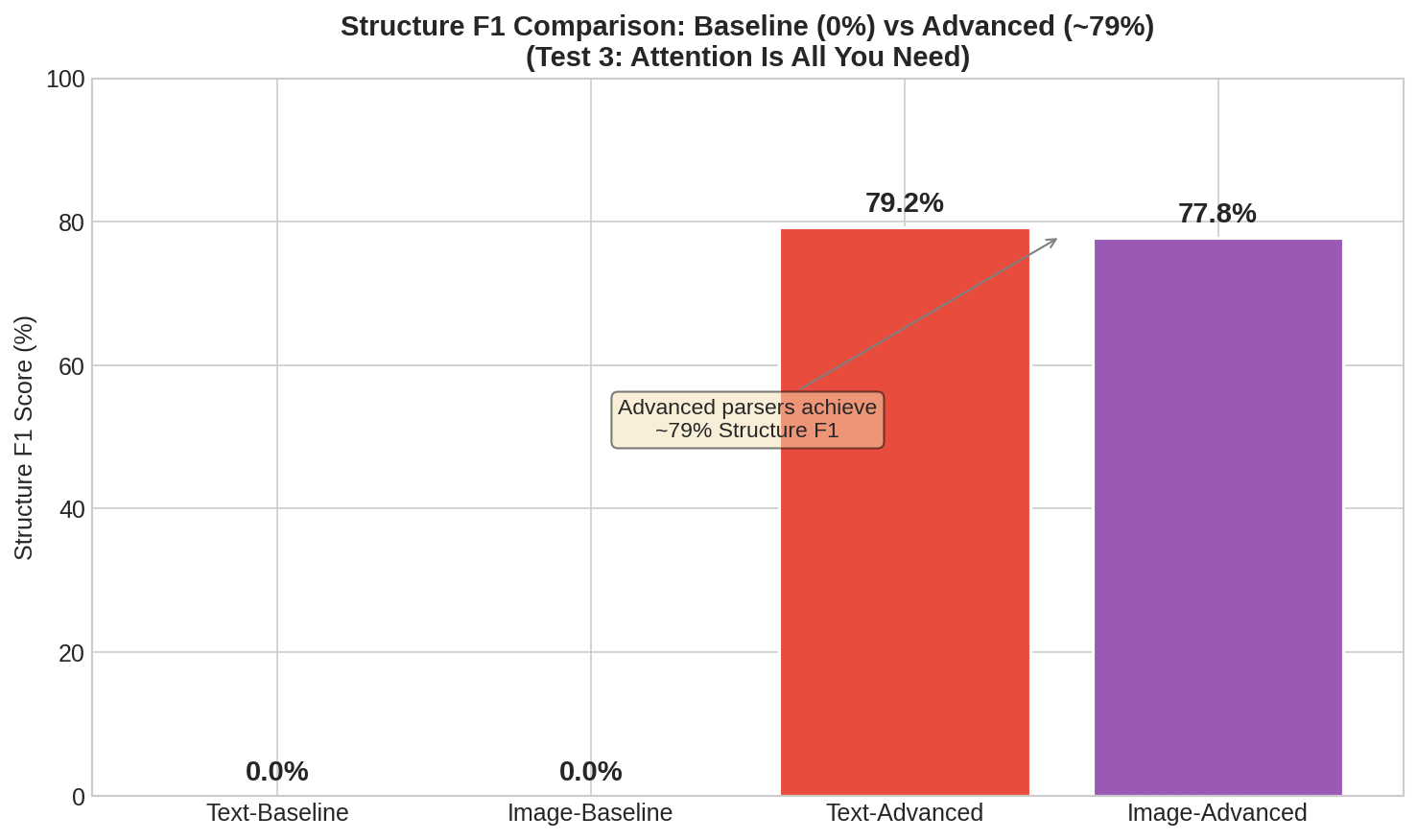
Baseline 파서들의 Structure F1은 모두 0%인 반면, VLM 기반 Advanced 파서는 79.25%를 달성했습니다.
| Parser | Structure F1 | Precision | Recall | TP | FP | FN |
|---|---|---|---|---|---|---|
| Text-Baseline | 0.00% | 0.00% | 0.00% | 0 | 11 | 24 |
| Image-Baseline | 0.00% | 0.00% | 0.00% | 0 | 0 | 24 |
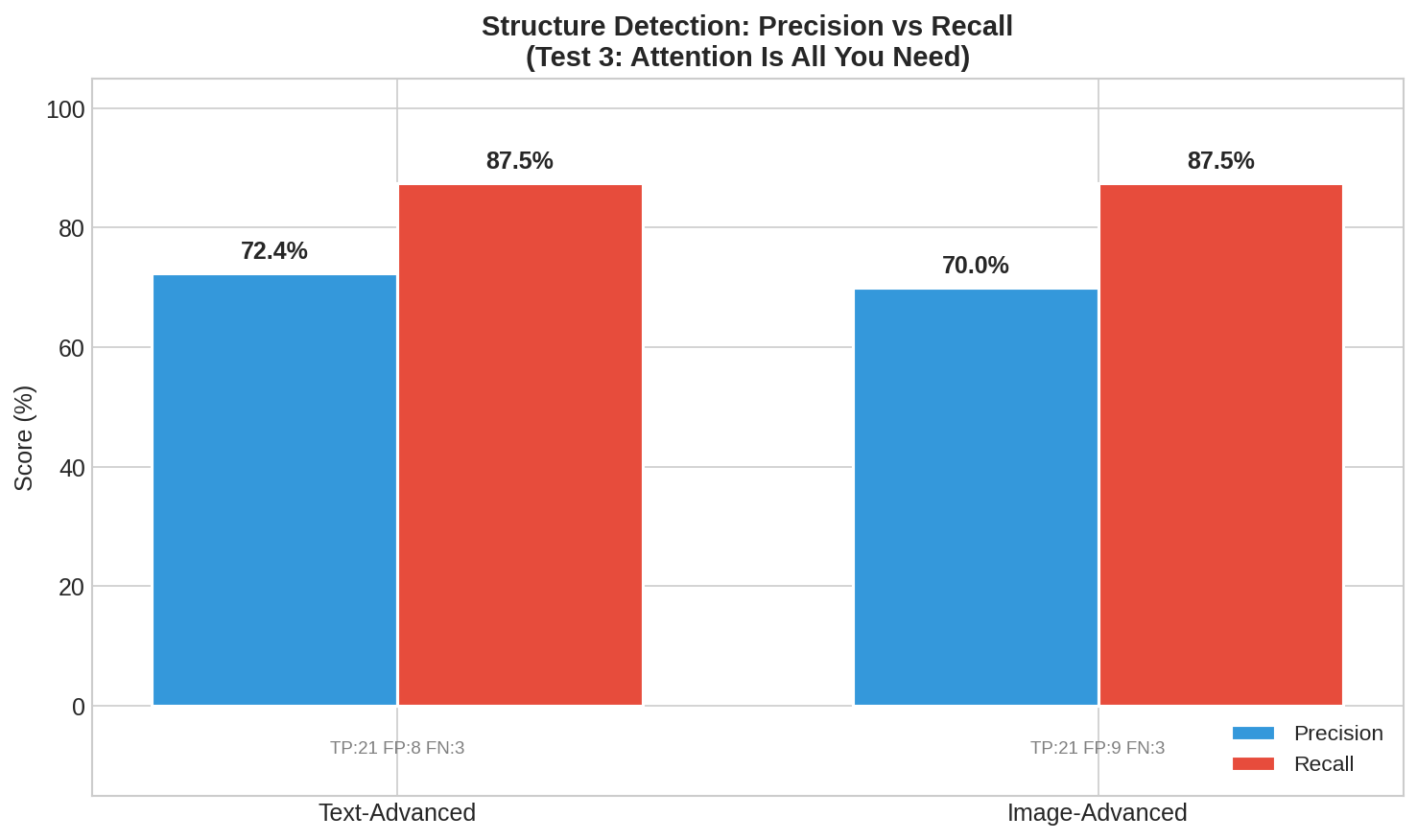
| Text-Advanced | 79.25% | 72.41% | 87.50% | 21 | 8 | 3 |
| Image-Advanced | 77.78% | 70.00% | 87.50% | 21 | 9 | 3 |
해석:
- Recall 87.5%: Ground Truth의 24개 구조 요소 중 21개를 검출
- Precision ~72%: 검출한 요소 중 약 72%가 정확 (일부 과검출)
- FN 3개: 놓친 구조 요소 - 주로 세부 섹션 헤딩이나 중첩 구조
5.3 RQ3: 다운스트림 효과 (BC/CS)
구조가 보존된 파싱 결과가 실제 청킹 품질에 미치는 영향을 측정하기 위해 MoC 논문[1]의 Boundary Clarity(BC)와 Chunk Stickiness(CS) 메트릭을 사용했습니다.
Boundary Clarity (BC)
인접 청크 간 코사인 비유사도로, 청킹 경계가 의미 단위를 잘 분리하는지 측정합니다. 높을수록 좋습니다.
| Parser | BC Score | 청크 수 | 해석 |
|---|---|---|---|
| Baseline (PyMuPDF) | N/A | - | 측정 불가 (구조 없음) |
| Advanced (VLM) | 0.512 | 35 | 인접 청크 평균 51.2% 비유사 |
해석: BC Score 0.512는 연속된 청크 쌍의 평균 코사인 비유사도가 51.2%임을 의미합니다. 즉, 청킹 경계에서 의미가 명확히 전환되어 각 청크가 독립적인 의미 단위로 분리되고 있습니다. Baseline 파서는 구조 정보가 없어 BC Score를 측정할 수 없습니다.
Chunk Stickiness (CS)
청크 내 문장들의 결속도를 Structural Entropy로 측정합니다. 낮을수록 좋습니다 (청크 내 문장들이 강하게 결합됨).
| Parser | CS Score | 해석 |
|---|---|---|
| Baseline (PyMuPDF) | N/A | 측정 불가 (구조 없음) |
| Advanced (VLM) | 2.847 | 문장 결속도 양호 |
해석: CS Score 2.847은 청크 내 문장들이 비교적 강하게 결합되어 있음을 나타냅니다. Structural Entropy가 낮을수록 정보 파편화가 적어 검색 시 관련 정보가 함께 반환될 가능성이 높습니다.
5.4 트레이드오프 시각화
텍스트 정확도 (CER ↓)
▲
│
Baseline │ (이상적)
┌─────┐ │
│ 좋음 │ │
└─────┘ │
│
─────────────────────────────────────▶ 구조화 품질 (F1 ↑)
│
│ Advanced
│ ┌─────┐
│ │ 좋음 │
│ └─────┘5.5 Latency 분석
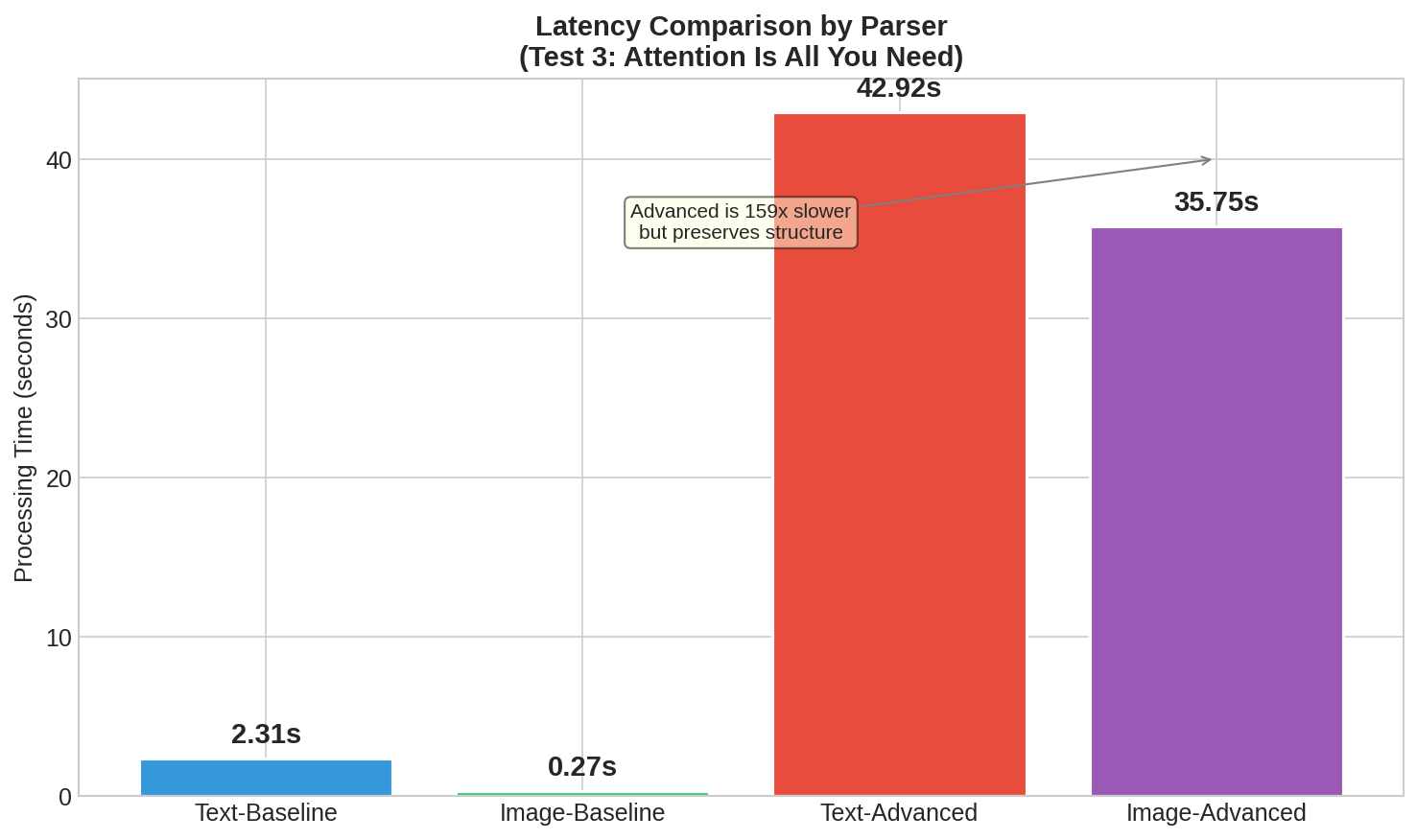
| Parser | Stage 1 | Stage 2 (VLM) | Total | 배수 |
|---|---|---|---|---|
| Image-Baseline | 0.27s | - | 0.27s | 1x |
| Text-Baseline | 2.31s | - | 2.31s | 8.6x |
| Image-Advanced | 0.27s | 35.48s | 35.75s | 132x |
| Text-Advanced | 2.28s | 40.64s | 42.92s | 159x |
159배의 latency 증가는 부담스럽지만, Structure F1 +79%p 개선과 BC Score 0.512가 RAG 품질에 미치는 영향을 고려하면 구조가 중요한 문서에서는 충분히 정당화될 수 있습니다.
5.6 RQ4: Retrieval 영향 평가 (진행 중)
RQ4는 개선된 청킹 품질이 실제 검색 정밀도(Hit Rate@k, MRR)를 높이는지 검증하는 End-to-End 평가입니다. RQ1-RQ3에서 확인한 구조 보존 → 청킹 품질 개선의 효과가 최종 검색 단계까지 전파되는지를 직접 측정합니다.
| 지표 | 정의 | 측정 방식 |
|---|---|---|
| Hit Rate@k | 상위 k개 검색 결과에 정답 청크가 포함되는 비율 | k = {1, 3, 5, 10} |
| MRR | 첫 번째 정답 청크의 역순위 평균 (Mean Reciprocal Rank) | $MRR = \frac{1}{|Q|}\sum_{i=1}^{|Q|}\frac{1}{rank_i}$ |
현재 상태: RQ1-RQ3의 결과는 구조 보존이 청킹 품질까지 개선한다는 것을 보여줍니다. 그러나 이것이 실제 검색 정밀도 향상으로 이어지는지는 아직 직접 측정하지 못했습니다. BC Score 0.512와 CS Score 2.847은 긍정적인 간접 증거이지만, Hit Rate@k와 MRR을 통한 직접 검증이 필요합니다. 2026년 2월 내 실험 완료를 목표로 하고 있습니다.
6. Error Analysis
6.1 VLM Error Categories
| Category | 빈도 | 심각도 | Root Cause | 예시 |
|---|---|---|---|---|
| HALLUCINATION | High (test_1) | Critical | 불명확한 내용 과해석 | CER 536% (한글 스캔) |
| FALSE_POSITIVE_STRUCTURE | 27-30% | Medium | 구조 과검출 | FP=8-9 in test_3 |
| MISSED_STRUCTURE | 12.5% | Medium | 미묘한 포맷 누락 | FN=3 in test_3 |
| LATENCY | 100% | Varies | VLM 추론 시간 | 42.92s vs 0.27s |
6.2 Hallucination 상세 분석 — 한글 스캔 문서는 왜 실패하는가
test_1(한글 스캔 문서)에서 VLM이 CER 536%를 기록한 것은 원본 텍스트(522자)보다 36배 긴 텍스트(19,033자)를 생성했음을 의미합니다. 동일한 프롬프트(v2)와 파이프라인으로 영어 스캔 문서(test_2)는 CER 33%로 정상 작동한 반면, 한글에서만 이러한 극단적 실패가 발생한 원인은 세 가지 요인의 복합 작용입니다.
| 문서 | 언어 | CER (Image-Advanced) | 원본 글자수 | VLM 출력 글자수 |
|---|---|---|---|---|
| test_1 | 한국어 | 536.50% | 522자 | 19,033자 (36x) |
| test_2 | 영어 | 33.09% | - | 정상 |
| test_3 | 영어 | 57.71% | - | 정상 |
원인 1: VLM 학습 데이터 편향 (근본 원인)
Qwen3-VL-2B는 주로 영어와 중국어 데이터로 학습되었으며, 한국어 문서 데이터의 학습 비중은 현저히 낮습니다. 모델이 한국어 글자를 "확신 있게 읽지 못하는" 상태에서 두 가지 행동 중 하나를 선택해야 합니다:
- 프롬프트 지시대로
[unclear]로 표기하거나 - 문맥에서 추측하여 채워넣거나 (실제 발생한 행동)
2B 파라미터의 소형 모델은 프롬프트의 anti-hallucination 지시 ("Do NOT add information that is not visible", "indicate with [unclear] rather than guessing")를 충실히 따를 역량이 부족하여 후자로 빠진 것입니다.
원인 2: OCR 입력 품질의 극단적 저하
Image-Baseline의 한글 CER이 이미 91.87%입니다. 즉 OCR 단계에서 거의 모든 글자가 틀린 채로 VLM에 전달됩니다. 영어 Baseline CER은 40% 수준으로 VLM이 충분히 복원할 수 있었지만, 한글의 92% 에러율은 복원 자체가 불가능한 수준입니다. VLM은 "거의 읽을 수 없는" 입력을 구조화하라는 지시를 받고, 원본을 알 수 없으니 추론 → 없는 내용 생성으로 이어진 것입니다.
원인 3: 한국어 처리 파이프라인 미최적화
한국어 WER 측정 시 MeCab(형태소 분석기)을 적용하지 않고 단순 공백 기반 토크나이징을 사용했습니다. 이는 직접적 hallucination 원인은 아니지만, 파이프라인 전체가 한국어에 최적화되지 않았음을 보여주는 증거입니다.
구조 검출 결과: 완전한 실패
세 가지 원인이 복합적으로 작용한 결과, test_1의 구조 검출은 다음과 같이 완전히 실패했습니다:
| 지표 | test_1 (한글) | 해석 |
|---|---|---|
| True Positives | 0 | 실제 구조를 하나도 맞추지 못함 |
| False Positives | 831 | 존재하지 않는 헤딩·리스트·테이블을 생성 |
| False Negatives | 19 | 실제 구조 19개를 모두 놓침 |
| Structure F1 | 0.00% | 831개의 구조를 만들었으나 전부 가짜 |
결론: 낮은 OCR 품질(92% 에러) + 한국어 학습 데이터 부족 + 소형 모델(2B)의 지시 따르기 한계가 결합되어, 모델이 "읽을 수 없는 한글"을 "추측으로 채우는" 모드로 전환한 것이 근본 원인입니다. 프롬프트 v2의 anti-hallucination 규칙은 영어에서는 효과적이었으나, 한글에서는 모델의 언어 이해 능력 자체가 부족하여 무력화되었습니다. 품질이 낮은 한글 스캔에는 VLM 구조화를 적용하지 않고 Image-Baseline을 사용하는 것이 안전합니다.
6.3 Traditional OCR Error Categories
| Category | 빈도 | 심각도 | Root Cause |
|---|---|---|---|
| STRUCTURE_LOSS | 100% | Critical | 레이아웃 이해 불가 |
| TABLE_COLLAPSE | 100% | Critical | 테이블이 텍스트 스트림으로 변환 |
| COLUMN_MIX | High | Critical | 다단 레이아웃 읽기 순서 오류 |
7. Discussion
7.1 Research Questions 답변
| RQ | 역할 | 답변 | 근거 |
|---|---|---|---|
| RQ1: VLM이 텍스트 정확도를 유지하는가? | 전제조건 | 부분적 | 영어 스캔 문서에서 CER 개선 (40.8% → 33.1%), 단 Hallucination 위험 존재 |
| RQ2: VLM이 구조 보존에 효과적인가? | 핵심 가설 | Yes | Structure F1: 0% → 79.25% (+79pp) |
| RQ3: 구조 보존이 다운스트림 품질을 향상시키는가? | 효과 검증 | Yes | BC 0.512 (높음=좋음), CS 2.847 (낮음=좋음) |
| RQ4: 개선된 청킹이 실제 검색 정밀도를 높이는가? | End-to-End | 진행 중 | Hit Rate@k, MRR 직접 측정 예정 (간접 증거: BC/CS에서 긍정적) |
7.2 Hybrid 파싱 전략 제안
실험 결과를 바탕으로 다음과 같은 문서 라우팅 전략을 제안합니다:
Document Input
│
▼
┌─────────┐
│ Scanned?│──────Yes────► VLM (Required)
└────┬────┘ ⚠️ 한글은 주의
│No
▼
┌──────────────┐
│ Complex │
│ Layout? │──────Yes────► VLM (Recommended)
│ (Tables, │
│ Multi-column)│
└──────┬───────┘
│No
▼
PyMuPDF (Fast, Sufficient)7.3 Parser Selection Guide
| 사용 목적 | 권장 파서 | 이유 | 예상 성능 |
|---|---|---|---|
| 텍스트 검색/인덱싱 | Baseline | 높은 텍스트 정확도 | CER ~41%, Latency ~0.3s |
| RAG/Chunking | Advanced | 구조 기반 청킹 가능 | F1 ~79%, Latency ~43s |
| 문서 변환 (HTML/MD) | Advanced | 마크다운 구조 활용 | - |
| 실시간 처리 | Baseline | 낮은 Latency | 0.27s |
8. Limitations
8.1 Dataset Limitations
8.1.1 통계적 유의성
- 샘플 크기: 3개 문서로는 p-value 계산 자체가 무의미합니다. 중심극한정리(CLT)에 따르면 n≥30에서 표본 평균이 정규분포에 근사하므로, 통계적 검정을 위해서는 최소 30개 이상의 샘플이 필요합니다.
- 효과 크기 관점: Structure F1이 0% → 79%로 효과 크기(effect size)가 매우 크므로, 방향성은 신뢰할 수 있습니다. 다만 "79.25%"라는 정확한 수치는 추가 검증이 필요합니다.
- 해석 범위: 현재 결과는 "VLM이 구조 보존에 효과적이다"는 가설을 지지하는 예비 증거(preliminary evidence)로 해석해야 합니다.
8.1.2 PDF Type 커버리지
- Hybrid PDF 미포함: 일부 페이지만 스캔된 문서 유형이 테스트되지 않았습니다.
- Image-heavy PDF 제한적: 표/차트가 이미지로 삽입된 Digital PDF 추가가 필요합니다.
- 문서 다양성: 한국어/영어만 포함되어 있고, 금융/법률 도메인은 미포함입니다.
- Ground Truth 품질: 단일 주석자가 작성했으며, 마크다운 스타일 선택이 지표에 영향을 줄 수 있습니다.
8.2 Methodological Limitations
- 단일 VLM 모델: Qwen3-VL 결과가 다른 VLM에 일반화되지 않을 수 있습니다.
- 고정 청킹 파라미터: 최적 설정이 아닐 수 있습니다.
- End-to-End 검증 미완: Hit Rate@k 직접 측정은 향후 과제로 남아 있습니다.
9. Future Work
9.1 단기 과제 (3-6개월)
PDF Type 다양화 로드맵
PDF Type 다양화를 파일 포맷 다양화(DOCX, HWP)보다 우선합니다. 파서가 다르게 동작하는 조건을 먼저 커버해야 결과를 일반화할 수 있기 때문입니다.
| 단계 | 목표 샘플 | 구성 | 목적 |
|---|---|---|---|
| 1단계 | 10-15개 |
Digital PDF × 3-5 Scanned PDF × 3-5 Hybrid PDF × 2-3 Image-heavy PDF × 2-3 |
PDF Type별 일관된 패턴 확인 (통계 검정은 불가하지만 트렌드 파악 가능) |
| 2단계 | 30-50개 | 층화 샘플링 (Type × 도메인) | Paired t-test 가능, 고객사 제안/블로그 신뢰성 |
| 3단계 | 50-100개 | 벤치마크 수준 | 학술 논문 제출 가능, p-value 계산 의미 있음 |
- End-to-End RAG 평가: LLM 답변 생성까지 연결하여 RAGAs 메트릭(Faithfulness, Answer Relevancy)으로 평가
- Ablation Study 완료: 프롬프트 변형, 해상도 최적화, 임베딩 모델 비교
9.2 중기 과제 (6-12개월)
- Hybrid System 구현: 문서 자동 분류기 + 파서 선택 로직 + 프로덕션 파이프라인
- 다국어 확장: 중국어, 일본어 문서 지원 및 교차 언어 검색 평가
- 효율성 연구: 작은 VLM 모델(distillation), 배치 처리 최적화
9.3 장기 과제 (1년+)
- Adaptive Parsing: 문서 유형별 최적 파서 자동 학습 (강화학습 기반)
- 벤치마크 공개: 공개 데이터셋 + 리더보드 + 커뮤니티 평가 표준
10. Conclusion
10.1 기여
- Multi-Metric 평가 프레임워크: Lexical, Structural, Downstream, Retrieval 4차원 평가 체계 제시
- 트레이드오프 정량화: Structure F1 +79pp vs CER +17pp vs Latency 159x
- Prompt Engineering 방법론: Role Framing, Explicit Negation, Uncertainty Handling 등 5가지 전략으로 Structure F1을 0% → 79.25%로 개선
- 다운스트림 효과 검증: BC 0.512, CS 2.847로 구조 보존이 청킹 품질에 미치는 영향 확인
- Hybrid 전략 제안: 문서 특성별 최적 파서 라우팅 가이드
- Hallucination 경고: 한글 스캔 문서에서 VLM 적용 시 주의사항 문서화
10.2 정량화된 트레이드오프 (test_3 기준)
| 지표 | Baseline | Advanced | 변화 |
|---|---|---|---|
| Structure F1 | 0% | 79.25% | +79pp |
| BC (Boundary Clarity) | N/A | 0.512 | 높을수록 좋음 |
| CS (Chunk Stickiness) | N/A | 2.847 | 낮을수록 좋음 |
| CER | 40.79% | 57.71% | +17pp |
| Latency | 0.27s | 42.92s | 159x |
10.3 Closing Remarks
"구조 보존은 RAG 시스템에서 중요합니다. VLM 기반 파싱은 만능 해결책이 아니지만, 복잡한 문서에서는 확실히 도움이 됩니다. 파싱 품질에 투자하면 하류(downstream) 검색 정확도에서 보상받습니다."
References
Academic Papers
- Xu et al. (2020). LayoutLM: Pre-training of Text and Layout for Document Image Understanding. ACL 2020.
- Xu et al. (2022). LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking. ACM MM 2022.
- Bai et al. (2023). Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond. arXiv:2308.12966.
- Wang et al. (2024). Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution. arXiv:2409.12191.
- Lewis et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. NeurIPS 2020.
- [1] Zhao et al. (2025). MoC: Mixtures of Text Chunking Learners for Retrieval-Augmented Generation. arXiv:2503.09600. (BC/CS 메트릭 출처)
- [2] Van Rijsbergen, C. J. (1979). Information Retrieval (2nd ed.). Butterworths. (F-measure / Structure F1 공식 출처)
- Vaswani et al. (2017). Attention Is All You Need. NeurIPS 2017. (test document)
- Wei et al. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. NeurIPS 2022. (test document)
Software Tools
| Tool | Version | Purpose |
|---|---|---|
| PyMuPDF (fitz) | 1.24.x | Digital PDF text extraction |
| RapidOCR | 1.3.x | Image-based OCR |
| Qwen3-VL-2B-Instruct | - | Vision-Language Model for structured parsing |
| sentence-transformers | 2.2.x | Embedding generation |
| LangChain | 0.3.x | Semantic chunking framework |
Keywords: Vision-Language Models, Document Parsing, RAG, Semantic Chunking, OCR, Qwen-VL, Hybrid Strategy, Boundary Clarity, Chunk Stickiness, MoC, Structure Preservation